
rmlint — консольная утилита для Unix-like систем, которая ищет файловый мусор по содержимому и структуре, а не только по имени. Основной сценарий — rmlint поиск дубликатов в каталогах, резервных копиях, фотоархивах, медиатеках, пользовательских папках и серверных хранилищах. Программа также находит пустые файлы, рекурсивно пустые каталоги, битые символические ссылки, nonstripped binaries и файлы с некорректным user или group ID.
Главное отличие rmlint от простых утилит очистки — раздельные этапы анализа и удаления. rmlint не меняет файловую систему сразу после сканирования: сначала формирует отчёт, выводит найденные группы и создаёт исполняемый сценарий rmlint.sh. Пользователь открывает этот сценарий, проверяет, какие файлы считаются оригиналами, какие попадают в удаление, и только после этого запускает действие. Для автоматизации дополнительно создаётся rmlint.json, поэтому rmlint программа подходит не только для ручной очистки, но и для регулярных задач администратора.
rmlint Linux-сценарии раскрывает лучше всего: программа рассчитана на командную строку, умеет работать с большими наборами файлов, поддерживает разные форматы вывода и даёт гибкие правила выбора оригинала. Для тех, кому нужен визуальный просмотр, предусмотрен rmlint GUI под названием Shredder. Он запускает rmlint в фоне, показывает дерево результатов, диаграмму распределения дубликатов, редактор сценария и настройки, похожие на параметры командной строки.
Краткая карточка rmlint
| Параметр | Описание |
| Название | rmlint |
| Назначение | поиск дубликатов файлов, дубликатов каталогов и других типов файлового мусора |
| Основной интерфейс | командная строка |
| Графический интерфейс | Shredder |
| Основные платформы | Linux, FreeBSD, Darwin/macOS, Solaris |
| Основной фокус | Linux и Unix-like окружения |
| Тип поиска | по содержимому, хешам, дополнительным признакам и правилам ранжирования |
| Что создаётся после стандартного запуска | rmlint.sh и rmlint.json |
| Форматы вывода | shell script, pretty, summary, JSON, CSV, fdupes-подобный вывод, progressbar, uniques, stamp |
| Лицензия | GPLv3 |
| Подходящая аудитория | опытные пользователи Linux, администраторы, пользователи NAS, разработчики, владельцы больших архивов |
| Основное ограничение | требует внимательной проверки результата перед удалением |
rmlint не является классическим чистильщиком диска с одной кнопкой. Его задача — точно найти подозрительные файлы, показать их в понятном виде и подготовить управляемое действие. Поэтому rmlint как пользоваться обычно объясняют через последовательность: выбрать область сканирования, изучить отчёт, проверить rmlint.sh, затем выполнить сценарий или изменить его.
Какие задачи решает rmlint
rmlint рассчитан на ситуации, где одинаковые файлы занимают место, мешают обслуживанию каталога или усложняют перенос данных. Программа особенно полезна, когда копии имеют разные имена: например, один и тот же архив лежит как project.zip, project-final.zip и project-copy.zip, а внутри хранится одинаковое содержимое. Поиск только по имени такие совпадения не покажет, а rmlint сравнивает содержимое и объединяет одинаковые файлы в группы.
Программа ищет несколько типов проблем:
- duplicate files — точные дубликаты файлов;
- duplicate directories — каталоги с одинаковым содержимым;
- empty files — файлы нулевого размера;
- recursive empty directories — пустые каталоги, включая вложенные пустые структуры;
- broken symlinks — символические ссылки, указывающие на отсутствующие цели;
- nonstripped binaries — бинарные файлы с отладочными символами;
- files with broken user or group ID — файлы, у которых владелец или группа не соответствуют существующим идентификаторам системы.
Эти категории важны для разных аудиторий. Домашний пользователь чаще применяет rmlint удалить дубликаты в папках Downloads, Documents, фотоархивах и на внешних дисках. Администратор использует JSON и CSV для отчётов, проверки пользовательских каталогов и повторной обработки результатов. Разработчику полезны поиск nonstripped binaries, пустых файлов и нестандартных артефактов после сборки.
rmlint не заменяет утилиты поиска похожих фотографий. Если два JPEG-файла выглядят почти одинаково, но имеют разное разрешение, другую степень сжатия или отличающиеся метаданные, rmlint считает их разными файлами. Для похожих изображений лучше использовать визуальные инструменты вроде Czkawka или dupeGuru. rmlint нужен для точных совпадений, где важна проверяемость результата.
Как устроена логика работы rmlint
rmlint принимает один или несколько путей, обходит файловое дерево, отделяет специальные категории мусора и затем ищет дубликаты среди оставшихся файлов. Если путь не указан, проверяется текущий рабочий каталог. По умолчанию скрытые файлы игнорируются, а символические ссылки не обходятся как обычные каталоги. Такой подход снижает риск случайно затронуть служебные структуры вроде .git.
Поиск дубликатов строится не на имени файла. rmlint использует признаки, которые помогают отсечь несовпадающие файлы до дорогого чтения содержимого: размер, частичные проверки, хеширование и дополнительные режимы сравнения. Для сценариев с повышенными требованиями доступен byte-by-byte comparison: такой режим полезен пользователям, которые не хотят полагаться только на хеш-суммы.
В каждой группе совпадающих файлов rmlint выбирает один файл как оригинал. Это не означает, что именно этот файл был создан первым. В терминологии rmlint оригинал — экземпляр, который программа предлагает оставить, а остальные элементы группы считаются копиями. Выбор зависит от порядка путей, времени изменения, глубины каталога, имени, количества hardlink и правил -S.
Базовая логика выбора выглядит так:
- если указано несколько путей, путь, названный раньше, имеет больший приоритет;
- если файлы находятся в одном пути, более старый файл обычно выигрывает по умолчанию;
- при одинаковых условиях применяется следующий критерий ранжирования;
- -S позволяет явно управлять тем, какой файл оставить.
Для архивов и резервных копий важен разделитель //. Пути после // считаются tagged paths и получают приоритет как места, где находятся оригиналы. Команда вида:
rmlint /media/old-backup // /home/user
помогает найти копии в старой резервной папке, которые уже есть в домашнем каталоге. Параметры --keep-all-tagged и --must-match-tagged усиливают этот сценарий: первый защищает tagged-файлы от удаления, второй оставляет в результате только группы, где есть совпадение с tagged-путём.
Основной интерфейс командной строки
Командная строка — главная рабочая среда rmlint. Базовый запуск выглядит минимально:
rmlint
Эта команда проверяет текущий каталог и выводит найденные элементы в терминал. Для конкретной папки путь указывается явно:
rmlint ~/Downloads
Для нескольких директорий достаточно перечислить их через пробел:
rmlint ~/Documents /media/archive
После стандартного запуска rmlint создаёт два важных файла:
- rmlint.sh — shell script с подготовленными действиями;
- rmlint.json — структурированный отчёт для повторной обработки, фильтрации и автоматизации.
rmlint.sh содержит команды, которые можно просмотреть и изменить. В нём оригиналы обычно представлены как сохраняемые элементы, а копии — как элементы для обработки. При стандартном сценарии используется удаление, но формат shell script поддерживает и другие обработчики: hardlink, symlink, reflink, clone, пользовательскую команду. Поэтому rmlint команда не обязана сводиться к удалению: её можно использовать для дедупликации через ссылки, если файловая система и задача это допускают.
Для больших каталогов полезен прогресс-бар:
rmlint -g ~/Videos
Параметр -g включает progressbar, summary, shell script, JSON и подробный уровень сообщений. Это удобнее, чем потоковый вывод тысяч строк, когда сканируется медиатека, резервный диск или сетевой каталог.
Форматы вывода и отчётов
rmlint поддерживает несколько форматов вывода. Это одна из причин, почему программа часто используется в сценариях администрирования: результат можно не только прочитать глазами, но и передать другим инструментам.
| Формат | Для чего нужен |
| sh | создаёт исполняемый shell script с действиями над найденными элементами |
| pretty | показывает цветной человекочитаемый вывод в терминале |
| summary | выводит итоговые счётчики и список созданных файлов |
| json | сохраняет все найденные элементы в структурированном виде |
| csv | подходит для табличной проверки и импорта в внешние инструменты |
| progressbar | показывает ход выполнения |
| fdupes | имитирует формат вывода fdupes для совместимости со старыми сценариями |
| uniques | выводит уникальные пути |
| stamp | создаёт временную метку запуска |
Стандартная конфигурация вывода включает sh:rmlint.sh, pretty:stdout, summary:stdout и json:rmlint.json. Если нужно добавить CSV, не отключая стандартные файлы, используется -O:
rmlint ~/Archive -O csv:/tmp/rmlint.csv
Если нужен только JSON в stdout, используется -o:
rmlint ~/Archive -o json
Разница между -o и -O принципиальна. -o переопределяет стандартный набор вывода, а -O добавляет новый формат к уже включённым. Для безопасной регулярной работы чаще удобнее -O, потому что rmlint.sh и rmlint.json остаются на месте.
JSON особенно полезен, когда результат нужно обработать автоматически: отфильтровать только крупные файлы, оставить группы из определённых каталогов, повторно отсортировать или передать данные в скрипт. CSV проще для визуального контроля в табличном редакторе, но JSON сохраняет больше структуры.
Shredder: графический интерфейс rmlint
Shredder — GUI-оболочка для rmlint. Она подходит пользователям, которым нужен визуальный обзор дубликатов без ручного чтения полного терминального вывода. Shredder не превращает rmlint в обычный очиститель по кнопке: итоговый принцип остаётся тем же — сначала сканирование, затем проверка, затем сценарий действий.
Запуск выполняется командой:
rmlint --gui
Shredder состоит из нескольких представлений: Location view, Runner view, Editor view и Settings view. Визуальный процесс повторяет логику CLI: пользователь выбирает каталоги, запускает сканирование, проверяет результаты, создаёт сценарий и только после этого выполняет действие.
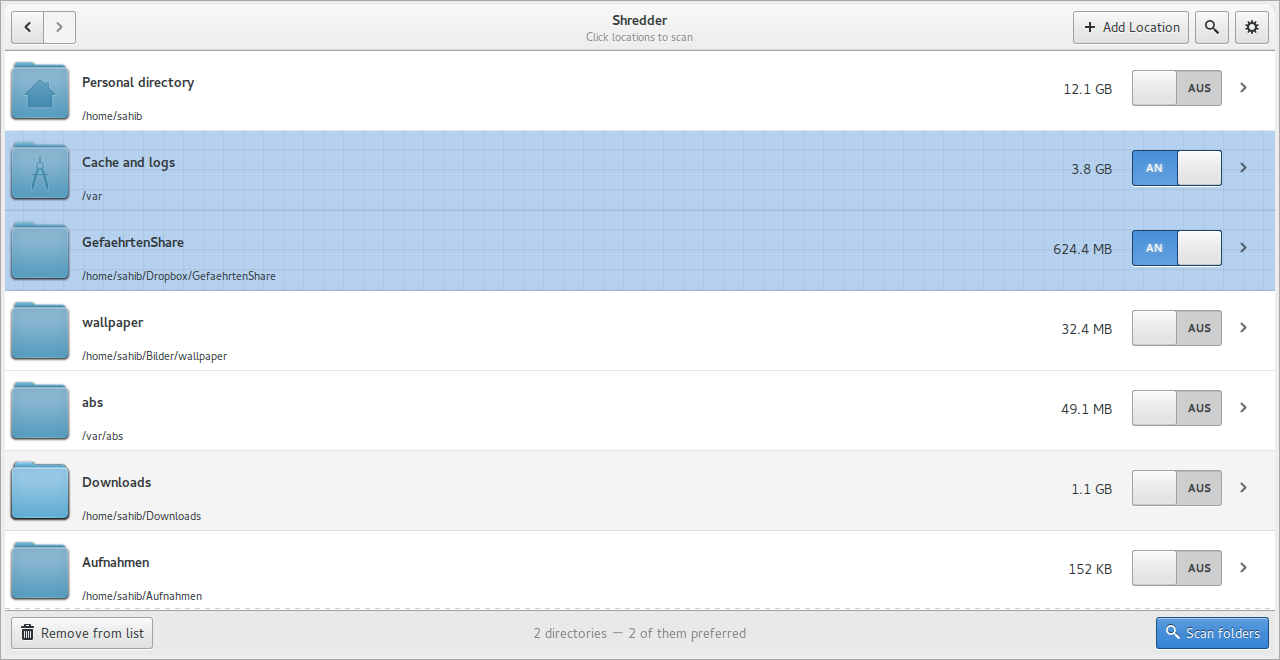
Location view
Location view используется для выбора каталогов. В этом окне Shredder показывает доступные расположения и позволяет добавить новый путь через файловый браузер. Пользователь выбирает одну или несколько директорий, после чего запускает проверку. На этом этапе удобно сразу разделить обычные и preferred paths: файлы в приоритетных путях будут рассматриваться как кандидаты на сохранение, если у них есть совпадающие копии в других местах.
Практический пример: есть каталог /home/user/Photos, где хранится основной архив, и внешний диск /media/old-photo-backup. В Shredder основной архив помечают как предпочитаемый путь, а внешний диск — как область, где нужно найти лишние копии. Это снижает риск удалить файл из основного архива и помогает работать не только с отдельными файлами, но и с целыми группами совпадений.
Location view хорошо подходит для первого знакомства с rmlint Shredder: здесь не нужно помнить параметры //, --keep-all-tagged и --must-match-tagged, но сам принцип выбора оригиналов остаётся тем же.
Runner view
После запуска сканирования Shredder переходит к Runner view. В левой части отображается дерево результатов, в правой — диаграмма распределения найденных совпадений по проверяемым каталогам. В дереве используются понятные маркеры: красный крест показывает файл, который Shredder предлагает удалить, зелёная галочка — файл, который будет сохранён.
Результаты сканирования Shredder с деревом найденных файлов и диаграммой
Runner view удобен при rmlint поиск дубликатов в больших каталогах. Вместо чтения длинного списка в терминале пользователь видит структуру: путь, размер, количество объектов и дату изменения. Если Shredder выбрал не тот экземпляр как сохраняемый, отметки можно изменить вручную. Это важная возможность для фотоархивов, резервных копий и каталогов проектов, где путь важнее даты изменения.
В верхней части доступен поиск по результатам. Фильтрация работает не только по фрагменту пути: можно ограничивать показ по размеру, времени изменения и количеству совпадений. Например, фильтр по крупным файлам помогает сначала обработать видео, ISO-образы и архивы, где освобождаемое место заметнее.
Кнопка Render script from переводит от просмотра к созданию сценария. Её не стоит нажимать до ручной проверки групп, где rmlint выбрал оригинал неочевидно: архивы, резервные копии, старые версии документов и каталоги с одинаковыми именами требуют отдельного внимания.
Editor view
Editor view показывает сгенерированный сценарий. Это не декоративный экран, а важный этап безопасной работы. Здесь можно просмотреть shell script, воспользоваться поиском, сохранить результат в .sh, .csv или .json, а затем решить, выполнять сценарий через Shredder или отдельно в терминале.
Редактор сценария в Shredder перед выполнением действий
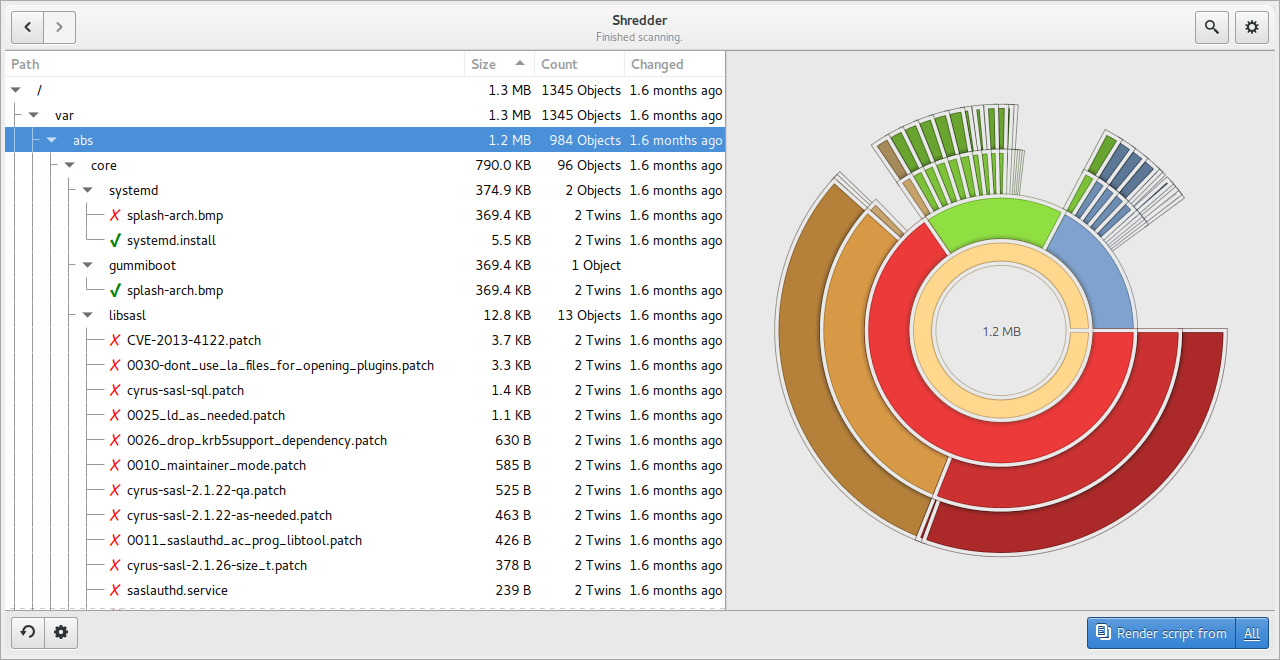
Кнопка Run Script выполняет подготовленный сценарий. Цвет кнопки имеет практическое значение: синий режим соответствует dry run, красный — реальному удалению файлов. Перед реальным запуском нужно проверить строки, где фигурируют важные каталоги, внешние диски, синхронизируемые папки и единственные копии документов.
Editor view особенно полезен тем, кто пока не готов полностью работать через CLI. Пользователь видит, какие команды подготовлены, но остаётся в графическом интерфейсе. При необходимости сценарий сохраняется и открывается в обычном редакторе, где можно удалить лишние строки, заменить действие или оставить только часть групп.
Settings view
Settings view управляет тем, как Shredder ищет дубликаты. Этот экран открывается через левое представление, пункт Settings или кнопку с шестерёнкой в Runner view. Параметры повторяют возможности командной строки, поэтому GUI не скрывает логику rmlint, а визуализирует её.
Настройки Shredder для rmlint
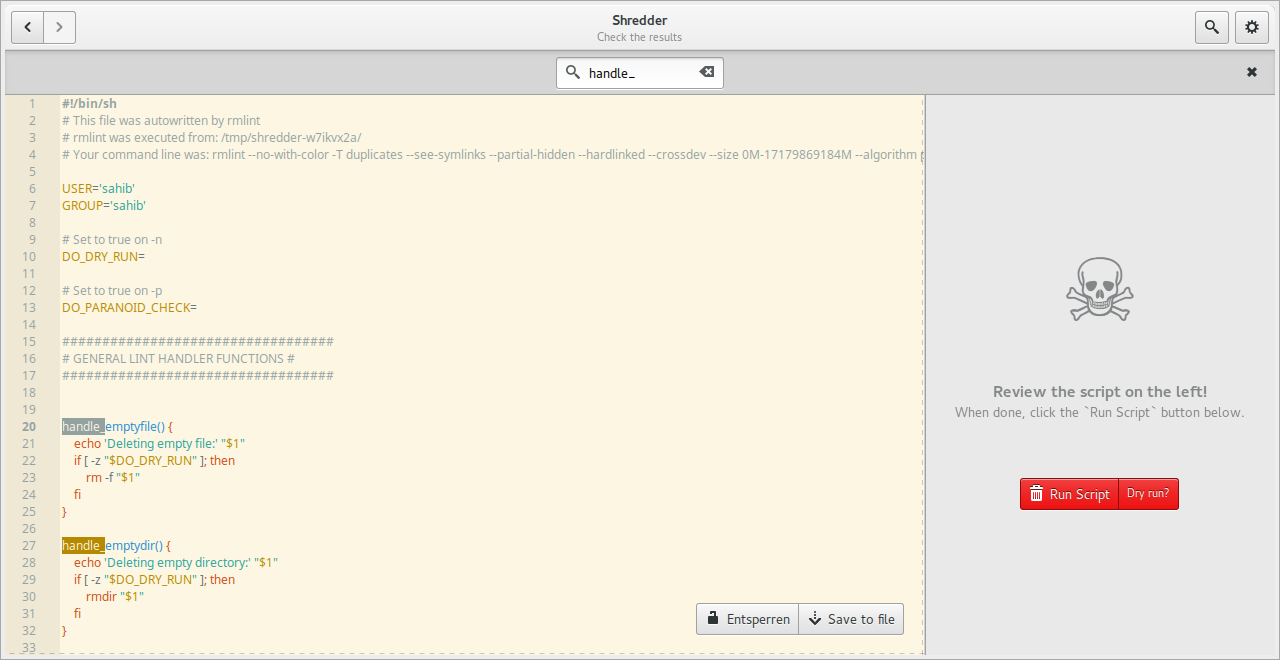
В настройках доступны группы Computation, General и Traverse. Здесь задаётся алгоритм хеширования, поведение символических ссылок, учёт duplicate hardlinks, поиск скрытых файлов и каталогов, переход через mountpoints и глубина обхода. Кнопка Apply применяет изменения, Reset to defaults возвращает стандартные настройки.
Новому пользователю лучше менять только те параметры, смысл которых понятен. Например, включение hidden files and directories полезно при анализе резервной копии, но опасно при проверке рабочего каталога с .git, .svn и служебными папками приложений. Переключение symbolic link handling влияет на то, будет ли rmlint рассматривать ссылки как самостоятельные объекты, следовать по ним или игнорировать.
Системные требования
rmlint работает в Unix-like окружениях. Основные платформы — Linux, FreeBSD, Darwin/macOS и Solaris, при этом основная оптимизация ориентирована на Linux. Для Windows rmlint не является нативной массовой GUI-программой в стиле dupeGuru или Czkawka, поэтому пользователям Windows обычно проще выбрать отдельный инструмент с поддержкой этой системы.
Базовая консольная часть rmlint требует системных библиотек, связанных с GLib и файловой системой. Для полноценной сборки и отдельных функций используются дополнительные зависимости: libblkid помогает определять mountpoints, libelf нужен для поиска nonstripped binaries, libjson-glib связан с обработкой JSON-данных и кэширующим слоем. Для документации и сборочного процесса используются scons, sphinx, gettext и стандартный набор компиляции.
GUI Shredder требует Python, GTK и PyGObject. Это отдельный слой поверх rmlint, поэтому ситуация rmlint команда работает, а rmlint –gui не запускается обычно связана не с самим поиском дубликатов, а с отсутствующими GUI-компонентами. На минимальных серверных установках Shredder часто не нужен: CLI быстрее вписывается в SSH-сеансы, cron-задачи и отчёты.
Ресурсные требования зависят от объёма данных сильнее, чем от самой программы. На маленькой папке Downloads rmlint завершается быстро и почти не создаёт нагрузки. На архиве из миллионов файлов важны скорость диска, тип файловой системы, количество мелких файлов, доступ к xattr, сетевые задержки и объём памяти. Режим дубликатов каталогов -D потребляет больше памяти, потому что программе нужно удерживать данные до завершения поиска и строить структуру для сравнения каталогов.
| Компонент | Что учитывать |
| CPU | хеширование и сравнение содержимого нагружают процессор при больших наборах файлов |
| Диск | HDD и сетевые хранилища сильнее ограничивают скорость, чем SSD |
| RAM | обычный поиск файлов легче режима -D, где нужно кэшировать больше данных |
| Права доступа | rmlint видит только файлы и каталоги, доступные текущему пользователю |
| Файловая система | hardlink, reflink, clone и xattr зависят от возможностей системы |
| GUI | Shredder требует GTK/PyGObject и графической сессии |
Перед запуском на сервере важно понимать права доступа. Если rmlint не может прочитать каталог, он не проанализирует его содержимое. Если пользователь запускает сценарий удаления без нужных прав, часть действий не выполнится. Запуск от root расширяет область доступа, но повышает цену ошибки: в таком режиме нельзя проверять весь / без строгих фильтров и понимания результата.
Основные возможности rmlint
Поиск дубликатов файлов
Поиск одинаковых файлов — главная задача rmlint. Программа сравнивает содержимое и группирует совпадения, даже если имена отличаются. Это удобно при очистке старых загрузок, объединении архивов, переносе данных между дисками и разборе резервных копий.
Пример базовой проверки:
rmlint ~/Downloads
После выполнения пользователь открывает rmlint.sh, проверяет, какие файлы помечены для удаления, и запускает сценарий только после просмотра. В rmlint обзор важно включать именно этот момент: безопасная работа строится не на доверии к первой выдаче, а на контроле подготовленных действий.
Для папки Downloads типовой результат понятен: копии установочных архивов, одинаковые PDF, повторно сохранённые изображения, старые файлы с суффиксами (1) и copy. Но даже здесь есть исключения. Дубликат может использоваться другой программой, быть частью структуры проекта или храниться в папке, где путь важен. rmlint показывает совпадение содержимого, а решение о ценности пути остаётся за пользователем.
Поиск дубликатов каталогов
Режим -D или --merge-directories позволяет искать duplicate directories. Это не просто поиск одинаковых имён папок. rmlint сравнивает содержимое дерева и может показать каталоги, которые содержат одинаковые данные. Такой режим полезен при разборе старых резервных копий, где целые папки копировались несколько раз.
Пример:
rmlint -D /media/archive
При работе с -D проверка результата обязательна. Дубликаты каталогов сложнее одиночных файлов: внутри могут быть скрытые файлы, символические ссылки, пустые элементы и вложенные структуры. rmlint учитывает такие детали, но пользователь должен понимать, почему один каталог выбран как сохраняемый, а другой предложен к удалению.
Режим -D не стоит запускать во время активного копирования, синхронизации или изменения файлов. Если содержимое каталога меняется в процессе анализа, итоговый список теряет надёжность. Для больших деревьев лучше остановить фоновые синхронизаторы, завершить копирование и только затем запускать rmlint.
Поиск пустых файлов и пустых каталогов
Пустые файлы не всегда являются мусором. В проектах они используются как маркеры, заготовки конфигурации, lock-файлы, .keep-файлы и элементы структуры. Поэтому rmlint показывает такие объекты отдельно от обычных дубликатов. Это помогает быстро найти пустые элементы, но не означает, что все они должны быть удалены.
Пустые каталоги тоже требуют проверки. После удаления дубликатов может остаться пустая вложенная структура, которую rmlint найдёт при повторном запуске. В резервных копиях пустые папки иногда сохраняют организацию проекта, поэтому удалять их автоматически нельзя. В домашней папке Downloads пустые каталоги чаще безопасны, а в рабочей директории приложения — нет.
Битые символические ссылки
Broken symlinks появляются после перемещения каталогов, отключения внешнего диска, переименования целевой папки или переноса данных между системами. rmlint находит такие ссылки как отдельный тип проблемных объектов. Это полезно после миграции домашнего каталога, разборки старых серверных данных и очистки архивов с Linux-конфигурациями.
Перед удалением битой ссылки нужно понять, почему цель недоступна. Если ссылка указывает на внешний диск, который сейчас не подключён, она не является мусором. Если ссылка осталась после удаления старой версии программы или переноса каталога, её можно убрать после проверки.
Nonstripped binaries
Nonstripped binaries — бинарные файлы с отладочной информацией. Для обычного домашнего пользователя этот тип результата редко важен. Для разработчика и администратора сборочного окружения он помогает увидеть, где остались бинарники с debug symbols, занимающие больше места и не предназначенные для обычного распространения.
rmlint не решает за пользователя, что делать с такими файлами. В отладочном окружении они нужны, в релизной сборке — часто нет. Поэтому этот режим полезен именно как диагностический отчёт.
Файлы с некорректным user или group ID
Файлы с broken user или group ID встречаются после переноса дисков между системами, восстановления из резервной копии, смены пользователей или миграции контейнеров. rmlint находит такие элементы, но удаление не является главным действием. Часто правильнее исправить владельца или группу через chown/chgrp, чем удалять файл.
Для администратора этот тип результата удобен как инвентаризация. Он показывает, где файловая система хранит объекты с идентификаторами, которых текущая система уже не знает.
Безопасность удаления и контроль результата
rmlint не удаляет файлы сразу после сканирования. Это важная защитная особенность: программа сначала создаёт отчёт и сценарий. Опасность появляется тогда, когда пользователь запускает rmlint.sh без чтения. Внутри сценария уже находятся команды, которые изменяют файловую систему.
Перед запуском сценария нужно проверить:
- совпадает ли проверяемый путь с ожидаемым каталогом;
- какие файлы считаются оригиналами;
- какие файлы будут удалены, заменены ссылками или обработаны другим способом;
- нет ли в списке единственных копий важных документов;
- не попали ли в результат каталоги синхронизации;
- подключены ли все внешние диски, на которые ссылаются symlink;
- завершено ли копирование в проверяемую папку;
- есть ли резервная копия перед массовым удалением;
- не затронуты ли служебные папки .git, .svn, .cache, профили приложений.
Для дополнительной защиты при удалении через сгенерированный shell script используется повторная проверка содержимого перед удалением. Запуск сценария с -p заставляет сценарий заново сравнить дубликат с оригиналом перед удалением. Это важно, если между сканированием и запуском сценария файлы могли измениться.
./rmlint.sh -p
При работе с hardlink и symlink нужно учитывать другое ограничение. Замена копий ссылками уменьшает занимаемое место или упрощает хранение, но меняет свойства набора файлов. При hardlink несколько путей начинают указывать на один inode. При symlink один путь становится ссылкой на другой. Для резервных копий, приложений и рабочих проектов такие изменения нужно применять только при полном понимании последствий.
Пошаговая инструкция: найти дубликаты в Downloads
Этот сценарий подходит для первого знакомства с rmlint. Папка Downloads обычно содержит повторно загруженные файлы, старые архивы, PDF, изображения и установочные пакеты, поэтому риск ниже, чем при проверке всего домашнего каталога.
Шаг 1. Перейдите в безопасную рабочую папку
Лучше запускать rmlint из отдельного каталога, где удобно хранить rmlint.sh и rmlint.json. Например:
mkdir -p ~/rmlint-reports cd ~/rmlint-reports
Так отчёты не смешиваются с содержимым Downloads. Это особенно удобно, если нужно сохранить результат проверки.
Шаг 2. Запустите сканирование
rmlint ~/Downloads
rmlint выведет найденные элементы в терминал и создаст файлы отчёта. Если файлов много, используйте progressbar:
rmlint -g ~/Downloads
Шаг 3. Откройте сценарий
less rmlint.sh
Проверьте строки с rm, rm -rf, hardlink или symlink, если использовались нестандартные обработчики. В обычном сценарии важно убедиться, что удаляются именно копии из Downloads, а не файлы из другого каталога.
Шаг 4. Проверьте JSON при необходимости
less rmlint.json
JSON удобен, если результат нужно сохранить, отправить на дополнительную обработку или повторно отфильтровать через --replay.
Шаг 5. Запустите сценарий только после проверки
./rmlint.sh
Сценарий запрашивает подтверждение перед выполнением. Для дополнительной проверки содержимого перед удалением используется:
./rmlint.sh -p
Шаг 6. Проверьте папку повторно
После удаления можно снова выполнить:
rmlint ~/Downloads
Повторный запуск должен показать меньше дубликатов. Если остались пустые каталоги, их нужно проверить отдельно: пустая папка не всегда является ошибкой.
Пошаговая инструкция: сравнить основной архив и резервную копию
При сравнении двух каталогов главная задача — не удалить файлы из основного архива. Для этого используется tagged path через //.
Допустим, основной архив находится в /data/archive, а старая резервная копия — в /media/backup-old. Нужно найти файлы в старой копии, которые уже есть в основном архиве.
rmlint --keep-all-tagged --must-match-tagged /media/backup-old // /data/archive
В этой команде /data/archive стоит после //, поэтому rmlint рассматривает его как tagged path. Параметр --keep-all-tagged защищает tagged-файлы от удаления. Параметр --must-match-tagged оставляет только те группы, где есть совпадение с tagged-путём.
Порядок здесь критичен. Если поменять местами архив и старую копию, приоритет изменится. Поэтому перед запуском на реальных данных полезно выполнить маленькую пробу на тестовых папках с несколькими файлами.
Проверка результата:
less rmlint.sh
В сценарии удаляемые строки должны относиться к /media/backup-old, а не к /data/archive. Если в списке есть действия над основным архивом, запускать сценарий нельзя: нужно исправить команду и повторить сканирование.
Для больших архивов после первого запуска можно использовать --replay. Он читает существующий rmlint.json, повторно форматирует, фильтрует или сортирует результат без нового полного обхода файловой системы. Это удобно, когда первичное сканирование заняло много времени, а затем нужно получить CSV, изменить сортировку или посмотреть только часть дерева.
Пошаговая инструкция: использовать Shredder
Shredder нужен, когда важно видеть результат не как длинный терминальный список, а как дерево с отметками сохранения и удаления. Этот вариант подходит для ручной разборки фотоархива, внешнего диска и домашней папки.
Шаг 1. Запустите GUI
rmlint --gui
Откроется Shredder. В первом представлении выбираются каталоги для анализа.
Шаг 2. Добавьте расположения
В Location view выберите один или несколько путей. Если нужно сравнить старую копию с основным архивом, отметьте основной архив как preferred path. Это соответствует CLI-логике, где tagged paths после // имеют приоритет при выборе оригинала.
Шаг 3. Запустите сканирование
После выбора путей запустите проверку. Shredder выполнит rmlint в фоне и перейдёт к Runner view. На этом этапе не нужно выполнять удаление: задача — изучить дерево результатов.
Шаг 4. Проверьте красные кресты и зелёные галочки
В Runner view красный крест означает кандидат на удаление, зелёная галочка — сохраняемый файл. При необходимости поменяйте отметки вручную. Это особенно важно, если дубликаты находятся в разных логических местах: например, один файл лежит в основном архиве, второй — в папке временной сортировки.
Шаг 5. Используйте фильтрацию
Отфильтруйте крупные группы или определённые каталоги. При разборе внешнего диска лучше сначала проверить самые большие файлы: видео, архивы, образы дисков. Это даёт быстрый эффект по освобождению места и снижает количество ручной проверки.
Шаг 6. Создайте сценарий
Нажмите Render script from после проверки дерева. Shredder сформирует сценарий и откроет Editor view.
Шаг 7. Просмотрите сценарий
В Editor view проверьте команды, воспользуйтесь поиском по пути и сохраните результат при необходимости. Если кнопка Run Script работает в dry run, действия не удаляют файлы. Красный режим предназначен для реального удаления и требует полной уверенности в результате.
Практические сценарии применения
Домашний пользователь
Домашний сценарий rmlint обычно связан с повторными загрузками, внешними дисками и папками документов. Программа помогает найти точные копии файлов, которые накопились после скачивания, пересылки через мессенджеры, распаковки архивов и ручного копирования.
Хороший стартовый набор каталогов:
- ~/Downloads;
- ~/Documents;
- папка с временными архивами;
- внешний диск со старыми копиями;
- каталог экспорта из телефона.
Для домашнего пользователя важнее не максимальная автоматизация, а понятная проверка. Лучше запускать rmlint на одной папке, изучать rmlint.sh, затем переходить к более крупным каталогам. Проверка всего домашнего каталога за один раз создаёт слишком много результатов и повышает риск ошибки.
Фото- и видеоархив
rmlint хорошо ищет точные копии исходников, видеофайлов, архивов RAW и экспортов, если содержимое полностью совпадает. Он не сравнивает изображения визуально, поэтому разные версии одного кадра остаются разными файлами. Это правильное поведение для архива: уменьшенная JPEG-копия, RAW-файл и отретушированный TIFF не должны попадать в одну группу.
Для фотоархива разумно разделять каталоги:
rmlint /media/old-photo-disk // /data/photo-master
Основной архив ставится после //, старая копия — до него. Так rmlint помогает найти файлы на старом диске, которые уже присутствуют в главном хранилище.
Для похожих фотографий и визуальных дублей стоит использовать другие инструменты. На freeexe доступны смежные страницы по работе с файлами и поиску: SearchMyFiles, Auslogics Duplicate File Finder, CloneSpy. Они закрывают другие пользовательские сценарии, особенно в Windows-среде.
NAS и внешние диски
На NAS rmlint полезен для медиатек, резервных копий и старых пользовательских папок. Главная сложность — права доступа, сетевые задержки и ссылки. Перед запуском нужно убедиться, что все сетевые тома подключены, а синхронизация остановлена.
Для NAS важно осторожно относиться к hardlink и reflink. Эти режимы могут быть полезны для экономии места, но зависят от файловой системы и политики хранения. Если архив используется несколькими приложениями, простое удаление копий иногда безопаснее, чем замена их ссылками.
Администратор Linux-сервера
Администратор использует rmlint не как визуальный очиститель, а как инструмент отчётности и контролируемого обслуживания. JSON и CSV позволяют сохранять результаты, сравнивать повторные проверки, формировать списки для ручного согласования и передавать данные в собственные скрипты.
Типовые задачи:
- проверить пользовательские каталоги на точные дубликаты;
- найти пустые файлы и пустые деревья после миграции;
- обнаружить broken symlinks после переноса путей;
- сформировать CSV-отчёт перед очисткой;
- применить --replay для повторной фильтрации результата;
- ограничить обход глубиной или mountpoint.
На сервере нельзя запускать rmlint на критических системных путях без строгих ограничений. Даже если rmlint сам не удаляет файлы, сгенерированный сценарий может содержать опасные действия при невнимательном запуске.
Разработчик
Разработчику rmlint помогает поддерживать порядок в деревьях сборки, временных каталогах, тестовых наборах и артефактах. Особенно полезны поиск nonstripped binaries, пустых файлов, одинаковых тестовых данных и дубликатов больших бинарных ресурсов.
В репозиториях нужно аккуратно работать со скрытыми каталогами. Стандартное игнорирование hidden files защищает от случайной обработки .git, но при намеренной проверке всего дерева включение hidden files требует отдельного контроля.
Работа рядом с файловыми менеджерами
rmlint хорошо сочетается с файловыми менеджерами и утилитами просмотра. После получения списка можно открыть нужные каталоги в Q-Dir, FreeCommander XE, Double Commander или Far Manager. Такой подход удобен, когда rmlint находит группы, а пользователь хочет визуально проверить соседние файлы и структуру папок перед запуском сценария.
Настройки и параметры, которые чаще всего нужны
Ограничение глубины обхода
Параметр -d или --max-depth ограничивает глубину рекурсии. Это полезно, если нужно проверить только верхний уровень каталога или избежать слишком глубокого обхода.
rmlint -d 2 ~/Archive
Такой запуск рассматривает каталог и ограниченное число вложенных уровней. Для большого архива это способ начать с верхней структуры и не уходить сразу в миллионы файлов.
Скрытые файлы
По умолчанию rmlint не включает скрытые файлы и каталоги. Это снижает риск затронуть служебные данные. Для осознанной проверки скрытых файлов используется:
rmlint --hidden ~/Project
Перед применением такого режима в репозиториях нужно исключить .git, .svn и другие служебные каталоги. Иначе результат может включать внутренние объекты систем контроля версий.
Символические ссылки
Поведение symlink управляется режимами followlinks, no-followlinks и see-symlinks. В стандартном поведении rmlint рассматривает ссылку как небольшой файл с путём к цели. При анализе duplicate directories это удобно: резервные копии с одинаковыми ссылками не превращаются в обход целевых директорий.
Если нужно реально следовать по ссылкам, используется другой режим, но такой запуск требует контроля циклов и понимания структуры. При очистке внешних дисков лучше сначала найти broken symlinks, а не включать обход ссылок без необходимости.
Mountpoints
Параметры crossdev и no-crossdev управляют переходом через границы файловых систем. По умолчанию rmlint может переходить через mountpoints. Если проверяется домашний каталог, внутри которого смонтирован внешний диск или сетевой ресурс, можно ограничить обход:
rmlint --no-crossdev ~
Это помогает избежать ситуации, когда пользователь хотел проверить локальную папку, а rmlint ушёл в подключённое хранилище.
Выбор оригинала через -S
-S управляет ранжированием внутри группы дубликатов. Например, -S a оставляет алфавитно первый путь, -S m — файл с меньшим mtime, -S M — файл с большим mtime, -S p — файл из пути, указанного раньше.
Пример:
rmlint -S a ~/Backups
Такой режим полезен для старых копий с понятными суффиксами, где алфавитный порядок помогает оставить базовое имя без приставок и временных обозначений.
Повторная обработка через --replay
--replay читает ранее созданный JSON и повторно выводит результат без нового полного чтения файловой системы. Это удобно после большого запуска:
rmlint /data/big-archive -g cp rmlint.json big-archive.json rmlint --replay big-archive.json /data/big-archive -O csv:/tmp/big-archive.csv
При replay-обработке rmlint игнорирует файлы, у которых изменился mtime относительно JSON. Это защитный механизм: если файл менялся после сканирования, старый результат для него нельзя использовать как основание для удаления.
Плюсы и минусы rmlint
Плюсы:
- ищет не только duplicate files, но и duplicate directories, empty files, recursive empty directories, broken symlinks, nonstripped binaries и файлы с broken user/group ID;
- не удаляет данные сразу после анализа, а создаёт проверяемый rmlint.sh;
- параллельно сохраняет rmlint.json, пригодный для автоматизации и повторной обработки;
- поддерживает CSV и другие форматы вывода;
- умеет работать с preferred/tagged paths через //;
- даёт гибкое ранжирование оригиналов через -S;
- поддерживает режим --replay для повторной фильтрации больших результатов;
- имеет GUI Shredder для визуальной проверки дерева и сценария;
- подходит для SSH, серверов, NAS и скриптовых процессов;
- позволяет использовать не только удаление, но и hardlink, symlink, reflink, clone или пользовательскую команду.
Минусы:
- основной интерфейс требует уверенной работы с командной строкой;
- Shredder зависит от графического стека GTK/PyGObject;
- результат нельзя выполнять без просмотра rmlint.sh;
- режим duplicate directories сложнее обычного поиска одинаковых файлов и требует особой проверки;
- rmlint не ищет визуально похожие изображения;
- нативный Windows-сценарий уступает инструментам, изначально рассчитанным на Windows GUI;
- hardlink, reflink, clone и xattr зависят от возможностей файловой системы;
- при проверке больших архивов скорость ограничивается диском и количеством файлов;
- неверный порядок путей при использовании // меняет выбор оригиналов.
Сравнение с аналогами
rmlint стоит сравнивать не с абстрактными чистильщиками, а с конкретными программами, которые решают близкие задачи: rdfind, fdupes, jdupes, dupeGuru, Czkawka, CloneSpy, Auslogics Duplicate File Finder. У каждого подхода своя аудитория.
| Программа | Основной интерфейс | Сильная сторона | Ограничение относительно rmlint |
| rmlint | CLI + Shredder | автоматизация, JSON, CSV, rmlint.sh, duplicate directories, разные типы lint | требует проверки сценария и понимания CLI |
| rdfind | CLI | простой поиск дубликатов по содержимому | меньше фокуса на разных типах файлового мусора и GUI |
| fdupes | CLI | классический простой поиск дубликатов | меньше возможностей для сложного ранжирования, отчётов и сценариев |
| jdupes | CLI | действия с дубликатами, hardlink/symlink/reflink, кроссплатформенность | экспертные режимы требуют осторожности |
| dupeGuru | GUI | удобный визуальный поиск, в том числе по именам | слабее подходит для серверной автоматизации |
| Czkawka | GUI + CLI | похожие изображения, пустые папки, разные категории очистки | другой подход к отчётам и shell-сценариям |
| CloneSpy | GUI | Windows-сценарии поиска копий | не заменяет rmlint в Linux CLI и серверных задачах |
| Auslogics Duplicate File Finder | GUI | простая работа для Windows-пользователя | не ориентирован на Unix-like автоматизацию |
rmlint и rdfind
rdfind — близкий CLI-инструмент: он ищет одинаковые файлы по содержимому и полезен для резервных каталогов. rmlint шире: кроме duplicate files, он охватывает duplicate directories, empty files, broken symlinks, nonstripped binaries, broken user/group ID и разные форматы вывода. Для простого одноразового поиска rdfind понятнее, для автоматизированной проверки с отчётами rmlint гибче.
rmlint и fdupes
fdupes удобен как классическая утилита: указали каталог, получили группы дубликатов. rmlint сложнее, но и функциональнее. Он не только выводит совпадения, но и создаёт сценарий, JSON, summary, поддерживает ranked original selection, replay, обработчики hardlink/symlink/reflink и Shredder. Если нужна минимальная команда для просмотра дублей, fdupes проще. Если нужно обслуживать большие архивы и повторно обрабатывать результат, rmlint подходит лучше.
rmlint и jdupes
jdupes близок к rmlint по продвинутым действиям с дубликатами. Он поддерживает удаление, ссылки и дедупликацию, работает на Linux, Windows и macOS. rmlint сильнее в связке отчётов, типов lint и shell/JSON-процесса. jdupes интересен пользователям, которым нужна кроссплатформенность и прямые действия с копиями, rmlint — тем, кто строит проверяемый Unix-like процесс с сохранением результата.
rmlint и dupeGuru
dupeGuru ориентирован на GUI и удобен для обычного пользователя. Он умеет сравнивать имена и содержимое, а fuzzy matching помогает находить файлы с похожими названиями. rmlint работает иначе: он сильнее в командной строке, автоматизации, JSON, duplicate directories и контроле сценария. Для ручной работы на десктопе dupeGuru проще. Для SSH, NAS и регулярных отчётов rmlint практичнее.
rmlint и Czkawka
Czkawka — современный инструмент с GUI и CLI, который закрывает больше пользовательских категорий: дубликаты, похожие изображения, пустые папки, broken files и другие типы очистки. rmlint не пытается быть универсальным визуальным чистильщиком. Его сильная сторона — точный Unix-like процесс, shell script, JSON, replay и работа с правилами оригиналов. Для похожих фото лучше Czkawka, для контролируемой дедупликации больших каталогов — rmlint.
rmlint и Windows-инструменты
Для Windows-пользователей внутренние страницы freeexe вроде Auslogics Duplicate File Finder, Duplicate Remover Free и CloneSpy ближе по интерфейсу. Эти программы рассчитаны на визуальный сценарий: выбрать диск, нажать кнопку, посмотреть список. rmlint устроен иначе: он даёт больше контроля, но требует Unix-like среды и понимания последствий.
Отзывы пользователей и профильных материалов
У rmlint сложился образ инструмента для опытных пользователей. В технических обсуждениях чаще отмечают скорость, возможность просмотреть rmlint.sh, наличие rmlint.json, гибкость выбора оригиналов и пользу для NAS, больших архивов и Linux-серверов. Положительная оценка обычно связана не с простотой, а с контролем: программа показывает, что будет сделано, и оставляет пользователю возможность изменить сценарий.
Усреднённое мнение пользователей сети можно свести к нескольким тезисам:
- rmlint хорошо подходит для больших деревьев файлов, где простые GUI-инструменты становятся неудобными;
- rmlint.sh воспринимается как преимущество, потому что его можно читать и редактировать;
- rmlint.json ценят те, кто пишет собственные скрипты и повторно обрабатывает результат;
- Shredder помогает визуально проверить группы, но основной силой rmlint остаётся CLI;
- новичкам требуется время, чтобы понять //, -S, --replay, hardlink и symlink;
- перед первым реальным удалением пользователи обычно советуют запускать rmlint на тестовой папке.
В профильных Linux-материалах rmlint обычно ставят рядом с rdfind и fdupes. В таких сравнениях его описывают как более продвинутый инструмент: он не ограничивается списком одинаковых файлов, а создаёт сценарии, отчёты и поддерживает дополнительные категории файлового мусора. При этом авторы технических руководств подчёркивают осторожность: массовая очистка дубликатов безопасна только после просмотра результата.
Негативные оценки чаще относятся не к качеству поиска, а к сложности. Пользователю, который ждёт одну кнопку найти и удалить, rmlint кажется избыточным. Тем, кто обслуживает сервер, NAS или архив, эта же избыточность становится преимуществом: можно сохранить отчёт, повторно его отфильтровать, изменить сценарий и выполнить только проверенную часть.
Типичные ошибки при работе с rmlint
Запуск на слишком широкой области
Команда на весь домашний каталог или корень файловой системы создаёт слишком много результатов. Пользователь теряет контекст и повышает риск запустить сценарий с опасными действиями. Начинать лучше с одной понятной папки: Downloads, старый внешний диск, временный архив.
Выполнение rmlint.sh без чтения
Это самая опасная ошибка. rmlint не удаляет файлы сразу, но rmlint.sh уже содержит действия. Перед запуском сценарий нужно открыть и проверить. Особенно важны строки с rm -rf, duplicate directories и путями к основному архиву.
Неверный порядок путей с //
В команде с tagged paths путь после // получает приоритет как место оригиналов. Если перепутать порядок, rmlint будет сохранять не тот каталог. Для резервных копий это критично: основной архив должен быть защищён через tagged path и --keep-all-tagged.
Работа во время копирования
Нельзя анализировать каталог, который одновременно активно изменяется. Копирование, синхронизация, распаковка архивов и запись приложений меняют данные между сканированием и запуском сценария. Перед rmlint лучше завершить операции и убедиться, что каталог стабилен.
Поиск похожих фото как точных дубликатов
rmlint сравнивает содержимое, а не визуальное сходство. Разные версии одного фото, перекодированные изображения и файлы с изменёнными метаданными не являются точными дубликатами. Для них нужны программы с анализом изображений.
Игнорирование hidden files
По умолчанию hidden files не включаются, и это защищает служебные каталоги. Но при проверке резервной копии пользователь может ожидать, что будут проверены все данные. В таком случае нужно явно решить, включать скрытые элементы или нет, а затем проверить, не затронуты ли .git, .svn и системные папки приложений.
Непонимание hardlink и symlink
Hardlink и symlink не равны удалению. Они меняют структуру хранения и поведение путей. В простом домашнем сценарии безопаснее использовать стандартный remove после проверки. Ссылки стоит применять там, где пользователь понимает inode, границы файловых систем и последствия редактирования.
Как проверить результат после очистки
Проверка результата нужна не только для оценки освобождённого места. Она помогает убедиться, что важные каталоги сохранили ожидаемую структуру.
После выполнения сценария можно снова запустить:
rmlint ~/Downloads
Если сканировалась резервная копия:
rmlint --keep-all-tagged --must-match-tagged /media/backup-old // /data/archive
Повторный запуск должен показать меньше групп. Оставшиеся элементы нужно разобрать отдельно: они могут быть уникальными файлами, похожими, но не одинаковыми объектами, пустыми каталогами или служебными файлами.
Дополнительно стоит проверить:
- открываются ли важные документы;
- не пропали ли ожидаемые папки в основном архиве;
- не появились ли битые symlink после удаления;
- не нарушились ли проекты, где пустые файлы использовались как маркеры;
- соответствует ли освобождённое место ожидаемому объёму;
- сохранился ли rmlint.json для отчёта.
Для крупных задач полезно хранить отчёты по датам: отдельный каталог с rmlint.json, CSV и копией rmlint.sh позволяет вернуться к тому, что именно было найдено и какие действия планировались.
Для кого rmlint подходит
rmlint подходит пользователям, которым нужен контроль над каждым этапом. Это не самый простой путь, но один из самых управляемых.
| Сценарий | Подходит ли rmlint | Почему |
| Разовая очистка Downloads | подходит | простая команда, понятный rmlint.sh, быстрый результат |
| Большой фотоархив | подходит для точных копий | сравнивает содержимое, но не ищет визуально похожие фото |
| NAS | подходит | CLI, отчёты, JSON, контроль путей |
| Linux-сервер | подходит | работает в SSH и автоматизируется |
| Windows-десктоп | не основной сценарий | проще выбрать GUI-программу под Windows |
| Поиск похожих изображений | не подходит | rmlint ищет точные совпадения |
| Разбор резервных копий | подходит | //, --keep-all-tagged, --must-match-tagged защищают основной архив |
| Работа без чтения сценария | не подходит | rmlint.sh нужно проверять |
Опытному Linux-пользователю rmlint даёт точность и гибкость. Новичку лучше начать с Shredder или с маленького тестового каталога. Администратору полезны JSON, CSV и replay. Пользователю Windows проще смотреть в сторону GUI-аналогов на freeexe, например Auslogics Duplicate File Finder или CloneSpy.
Кому лучше выбрать другую программу
rmlint не стоит выбирать, если пользователь не готов читать сценарий перед удалением. В таком случае безопаснее GUI-инструмент, который требует ручного подтверждения групп и показывает результат в привычном интерфейсе.
Другой инструмент лучше подойдёт, если нужно:
- искать визуально похожие фотографии;
- работать только в Windows без Unix-like окружения;
- переносить дубликаты в отдельную папку без ручного редактирования сценария;
- пользоваться простым мастером очистки;
- удалять копии без изучения hardlink, symlink, tagged paths и -S;
- выполнять разовую задачу без терминала.
Для похожих фото и универсального GUI лучше Czkawka или dupeGuru. Для простой консольной проверки без сложной логики выбора оригинала — fdupes или rdfind. Для продвинутой кроссплатформенной дедупликации через ссылки — jdupes. Для Linux-автоматизации, отчётов и проверки больших архивов — rmlint.
FAQ
rmlint удаляет файлы сразу?
Нет. rmlint сначала показывает найденные элементы и создаёт отчёты. Файловую систему меняет не само сканирование, а запуск подготовленного сценария rmlint.sh или действия в Shredder после подтверждения.
Что такое rmlint.sh?
rmlint.sh — shell script с командами для обработки найденных элементов. Его нужно открыть, проверить и только затем запускать. В сценарии можно удалить строки, изменить команды или оставить только нужные группы.
Зачем нужен rmlint.json?
rmlint.json хранит структурированный результат запуска. Он используется для автоматизации, анализа, повторной обработки через --replay, экспорта и интеграции с внешними скриптами.
Чем Shredder отличается от обычного rmlint?
Shredder — графическая оболочка. Она запускает rmlint, показывает дерево результатов, диаграмму, редактор сценария и настройки. При этом сама логика поиска остаётся rmlint.
Можно ли найти дубликаты только во втором каталоге?
Да. Для этого основной каталог помещают после //, а проверяемую копию — до него. Важные параметры для такого сценария: --keep-all-tagged и --must-match-tagged.
Можно ли использовать rmlint для фотоархива?
Да, если нужны точные копии. rmlint найдёт одинаковые RAW, JPEG, видео и архивы, если содержимое совпадает. Для визуально похожих кадров нужен другой инструмент.
Что значит оригинал в rmlint?
Оригинал — файл, который rmlint предлагает оставить в группе совпадений. Это не обязательно самый первый созданный файл. Выбор зависит от путей, времени, имени и правил ранжирования.
Как управлять выбором оригинала?
Используется параметр -S. Он позволяет сортировать кандидатов по времени изменения, алфавиту, порядку путей, глубине каталога, длине имени и другим критериям. Для важных архивов лучше использовать tagged paths через //.
Можно ли не удалять, а заменить копии ссылками?
Да. Shell-formatter поддерживает hardlink, symlink, reflink, clone и пользовательские команды. Эти режимы требуют понимания файловой системы и последствий для приложений.
Что делать, если Shredder не запускается?
Консольная часть rmlint остаётся рабочей, если сама команда доступна. Проблемы Shredder обычно связаны с графическими зависимостями GTK/PyGObject или отсутствием GUI-компонентов в среде.
Почему после очистки остались пустые папки?
Пустые каталоги могут появиться после удаления дубликатов. Их нужно проверить отдельным запуском rmlint. В некоторых проектах пустые папки являются частью структуры, поэтому автоматическое удаление не всегда правильно.
Подходит ли rmlint для серверов?
Да. CLI, JSON, CSV, progressbar и replay делают rmlint удобным для серверных задач. На сервере особенно важны ограничения области сканирования, права доступа и проверка сценария перед выполнением.
Итог
rmlint — инструмент для пользователей, которым нужен точный и проверяемый поиск дубликатов, а не автоматическая очистка без контроля. Его сильная сторона — сочетание CLI, Shredder, rmlint.sh, rmlint.json, CSV, replay, tagged paths и гибкого выбора оригиналов. Программа хорошо подходит для Linux, NAS, серверов, больших архивов, резервных копий и технических сценариев, где важны отчётность и возможность проверить каждое действие.
Для первой проверки достаточно запустить rmlint на небольшой папке, открыть rmlint.sh, изучить выбор оригиналов и выполнить сценарий только после просмотра. Для основного архива и резервной копии нужно использовать //, --keep-all-tagged и --must-match-tagged. Для визуальной проверки удобен Shredder: он показывает дерево, отметки удаления и сохранения, диаграмму и редактор сценария.
rmlint не стоит выбирать тем, кто хочет нажать одну кнопку и не читать результат. Но для контролируемой очистки, автоматизации и работы с большими Unix-like файловыми деревьями это один из самых практичных вариантов.
Список изменений
История версий и развитие программы:
- История rmlint важна для понимания характера программы. Проект начинался как консольный инструмент для поиска файлового мусора, затем был переписан и получил более развитую архитектуру, форматированный вывод, JSON, режимы выбора оригиналов и GUI-оболочку.
- Старые обсуждения rmlint описывали его как fast and light duplicate/lint finder: инструмент на C для удаления разных типов lint — дубликатов, пустых файлов, пустых каталогов, странных имён, старых временных данных и битых ссылок. После переписывания акцент сместился на более строгую обработку больших наборов файлов, отчёты, сценарии и безопасность удаления.
- Линия 2.2.0 запомнилась улучшением скорости, снижением потребления памяти и работой с очень большими наборами данных. Для пользователей больших архивов это был важный этап: rmlint стал восприниматься не только как небольшая утилита, но и как инструмент для многомиллионных деревьев файлов.
- Линия 2.4.0 добавила заметный визуальный слой: появился Shredder, графический интерфейс на Python/GTK3. Это расширило аудиторию rmlint, потому что часть пользователей получила дерево результатов, диаграмму распределения и редактор сценария вместо работы только с терминалом.
- Линия 2.6.0 усилила файлово-системные сценарии. В ней появились изменения, связанные с btrfs, обработкой duplicate directories, progressbar, статистикой и ранжированием. Важным изменением стал переход стандартного алгоритма хеширования на blake2b. В той же ветке исправлялись проблемы shell script на отдельных платформах, что показывает главный приоритет проекта: не просто найти дубликаты, а сформировать корректный сценарий обработки.
- Линии 2.7.0, 2.8.0 и 2.9.0 развивали программу через исправления и небольшие функциональные дополнения. Для подобных утилит это нормальная траектория: после появления базовой архитектуры важнее стабильность, корректные сценарии, обработка граничных случаев и совместимость.
- Ветка 2.10.x продолжила линию исправлений и доработок. Среди заметных изменений этой ветки — replay unpacking, уточнения поведения отдельных параметров, совместимость с Solaris и дополнительные сборочные опции. Для пользователя это означает, что rmlint развивался не как одноразовый скрипт, а как поддерживаемый инструмент с вниманием к платформам, сценариям вывода и повторной обработке результатов.

Оставте свой отзыв о rmlint