
CuneiForm OCR, также известная как Cognitive OpenOCR, — программа для распознавания текста со сканов и изображений. Она превращает бумажные документы, отсканированные страницы, факсы, машинописные листы и графические файлы с печатным текстом в редактируемый результат. Основной сценарий — получить из изображения текст, который затем можно исправить, сохранить в RTF, TXT, HTML или открыть в текстовом редакторе.
CuneiForm относится к настольным OCR-инструментам старой школы: программа работает локально, не требует отправки документа в облачный сервис и рассчитана прежде всего на печатный текст. В Windows-версии заметен классический интерфейс с меню File, Edit, View, Recognition, Window, Help, панелью инструментов и мастером Recognition Wizard. В Linux-порту чаще используется командная строка или внешняя графическая оболочка, например Cuneiform-Qt.
Ссылка:
Главная особенность CuneiForm — сочетание бесплатного распространения, открытого исходного кода OCR-ядра и поддержки русского языка. Программа умеет распознавать документы с печатным текстом, анализировать структуру страницы, учитывать язык распознавания и сохранять результат в редактируемом виде. Командная версия поддерживает форматы html, hocr, native, rtf, smarttext, text, а также режимы --dotmatrix, --fax и --singlecolumn для отдельных типов исходников.
Краткая оценка CuneiForm выглядит так:
| Параметр | Что важно знать |
|---|---|
| Тип программы | OCR-система для распознавания печатного текста |
| Название | CuneiForm OCR, Cognitive OpenOCR |
| Основная задача | перевод скана или изображения в редактируемый текст |
| Платформы | Windows-версия; порт Cuneiform for Linux для Linux, FreeBSD, OS X и Windows-сборок через MSVC, MinGW, Cygwin |
| Языки распознавания | русский, английский, смешанный русский/английский и другие европейские языки |
| Форматы результата в командной версии | TXT, RTF, HTML, hOCR, smarttext, native |
| Работа со сканером | доступна в Windows-версии через мастер и драйвер сканера |
| Главный плюс | локальное распознавание без облака и без оплаты |
| Главное ограничение | результат нужно вычитывать, особенно после сложных сканов, факсов и многостолбцовых страниц |
CuneiForm удобен не как современный PDF-комбайн, а как отдельная программа для распознавания текста. Для чтения PDF лучше брать Adobe Acrobat Reader, Foxit Reader, Sumatra PDF или PDF-XChange Viewer. Для разделения и объединения PDF уместнее PDFsam или PDF Shaper Free. CuneiForm решает другую задачу: получить редактируемый текст там, где есть только картинка страницы.
Что такое CuneiForm OCR
CuneiForm OCR — система оптического распознавания символов, разработанная Cognitive Technologies. Изначально CuneiForm была Windows-программой, затем OCR-ядро стало открытым, а порт Cuneiform for Linux перенёс программу в Unix-подобные рабочие сценарии. В Linux-порте CuneiForm описывается как многоязычная OCR-система, изначально созданная для Windows и перенесённая на Linux Юсси Пакканеном.
В прикладном смысле CuneiForm берёт изображение страницы и строит текстовый результат. На вход попадает скан, фотография документа или графический файл. На выходе пользователь получает текст, который можно редактировать, копировать, сохранять и использовать в Word, LibreOffice Writer, HTML-документе или текстовом файле. Поэтому CuneiForm часто ищут как бесплатную OCR программу, программу для распознавания текста, OCR для Linux, OCR программу для Windows, инструмент для перевода скана в редактируемый текст.
CuneiForm не просто считывает символы по одному. Она выполняет анализ страницы: определяет текстовые блоки, пытается сохранить логическую структуру документа, распознаёт формат текста и затем формирует результат. В командной документации прямо выделены три задачи: text recognition, layout analysis и text format recognition.
Практические сценарии, где CuneiForm остаётся понятным инструментом:
распознать страницу книги или инструкции;
получить текст из отсканированного договора;
перевести старую машинописную страницу в редактируемый документ;
разобрать факсовую копию;
обработать изображение с русским или английским печатным текстом;
сохранить результат в RTF для дальнейшей правки;
получить обычный TXT без оформления;
использовать OCR-движок в терминале;
подключить CuneiForm к графической оболочке в Linux.
CuneiForm не относится к редакторам PDF, не заменяет офисный пакет и не предназначен для сложной ручной вёрстки. Программа занимается распознаванием текста. Если нужно редактировать PDF-страницы, менять объекты, добавлять подписи и работать с многостраничными PDF-пакетами, больше подходят PDF Commander, ABBYY FineReader PDF или другие PDF-редакторы. Если задача сводится к простому сканированию в PDF без глубокого OCR, полезнее смотреть в сторону WinScan2PDF или PaperScan Free.
Назначение программы
Главная задача CuneiForm — распознавание печатного текста. Пользователь получает изображение страницы со сканера, из папки или через внешнюю программу, выбирает язык распознавания и запускает OCR. После обработки текст можно исправить, сохранить или передать в текстовый редактор.
В Windows-версии процесс построен вокруг мастера Recognition Wizard. Мастер помогает выбрать источник изображения, настроить сканирование или открыть готовый файл, указать язык и перейти к распознаванию. Такой подход удобен для пользователя, которому не нужно помнить параметры командной строки.
В командной версии вся логика выражается одной строкой:
cuneiform -l rus -f rtf -o result.rtf scan.png
Эта команда распознаёт русский текст из изображения scan.png и сохраняет результат в RTF-файл result.rtf. Для смешанного русского и английского текста используется язык ruseng:
cuneiform -l ruseng -f text -o result.txt page.tif
Для одноколоночного документа есть режим --singlecolumn:
cuneiform --singlecolumn -l eng -f html -o result.html page.tif
CuneiForm особенно полезен, когда исходник содержит печатный текст без сложного дизайна: страница книги, инструкция, статья, типовой документ, архивная машинописная страница. На таких материалах OCR-движок выполняет свою основную задачу: отделяет символы от фона, собирает строки, учитывает язык и формирует текстовый файл.
Чем CuneiForm не является
CuneiForm не стоит воспринимать как универсальный современный комплекс для любой работы с документами. Программа не заменяет PDF-редактор, не создаёт офисные макеты с нуля и не занимается распознаванием рукописного конспекта. Её рабочая область — печатный текст на изображении.
Важно разделять несколько задач:
| Задача | Подходит ли CuneiForm | Что выбрать вместо неё |
|---|---|---|
| Распознать печатный текст со скана | Да | CuneiForm подходит |
| Сохранить распознанный текст в RTF или TXT | Да | CuneiForm подходит |
| Сделать PDF редактируемым внутри PDF-редактора | Нет | ABBYY FineReader PDF, PDF-редакторы |
| Просто просмотреть PDF | Нет | Sumatra PDF, Adobe Acrobat Reader |
| Разделить или объединить PDF | Нет | PDFsam, PDF Shaper Free |
| Быстро отсканировать страницу в PDF | Частично | WinScan2PDF, PaperScan Free |
| Распознать рукописный текст | Нет | специализированные OCR-инструменты |
Сильная сторона CuneiForm — локальное OCR без обязательной подписки и без облачного сервера. Ограничение — возраст интерфейса, необходимость вычитки и зависимость результата от качества исходного изображения.
Интерфейс CuneiForm
Главное окно Windows-версии
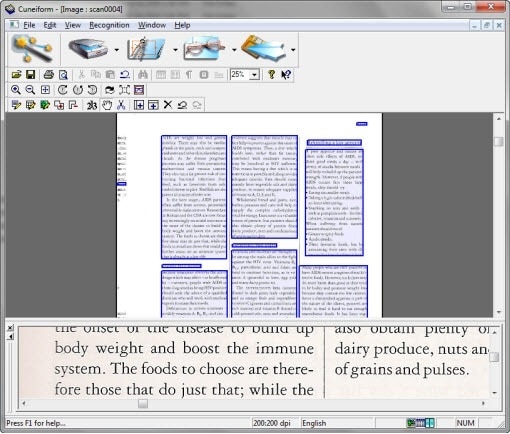
Windows-интерфейс CuneiForm выглядит как классическое настольное приложение. В верхней части расположено меню File, Edit, View, Recognition, Window, Help. Под меню находится панель инструментов с кнопками открытия файла, сканирования, запуска распознавания, управления масштабом и работы с областями страницы. Центральная часть окна используется для изображения документа, нижняя — для просмотра распознанного текста или фрагмента результата.
В главном окне хорошо видна логика OCR: программа показывает изображение страницы, выделяет текстовые блоки рамками и позволяет контролировать, какие зоны будут распознаны. На скане с газетной или книжной версткой CuneiForm определяет отдельные области, а пользователь видит, как программа разделила страницу на фрагменты.
Статусная строка помогает контролировать параметры документа: в примерах интерфейса отображается разрешение страницы, выбранный язык и служебные режимы вроде NUM. Это не декоративные элементы, а рабочие индикаторы: неправильный язык или слабое разрешение напрямую влияют на качество результата.
Русскоязычная сборка OpenOCR CuneiForm сохраняет ту же структуру: меню Файл, Правка, Вид, Распознавание, Окно, Справка; панель кнопок; рабочее поле с изображением; нижняя область с фрагментом распознанного текста.

Интерфейс не похож на современные минималистичные программы: в нём много маленьких кнопок, классические панели и отдельные инструменты для разметки страницы. Такой дизайн требует привыкания, зато показывает рабочую механику OCR. Пользователь видит не только итоговый текст, но и исходное изображение, зоны распознавания, масштаб, язык и параметры страницы.
Recognition Wizard
Recognition Wizard — основной сценарий для пользователя Windows-версии. Он ведёт по шагам: выбрать источник изображения, указать файл или сканер, настроить параметры и запустить распознавание. В мастере есть варианты работы с уже готовым изображением и со сканером. Для сканера используется драйвер, а при его отсутствии поле драйвера остаётся незаполненным.
В окне мастера используются привычные кнопки Back, Next, Cancel, Help. Это удобно для разовой задачи: пользователь не выбирает вручную каждую команду из меню, а проходит последовательность действий. При распознавании документов с разными языками важен этап выбора языка. Для русского документа выбирается русский, для английского — English, для смешанного русского и английского текста в командной версии используется ruseng.
Recognition Wizard помогает не пропустить базовые параметры, но не отменяет вычитку результата. После OCR текст нужно сверить с изображением, особенно если документ напечатан мелким шрифтом, содержит таблицы, имеет перекос или получен из факса.
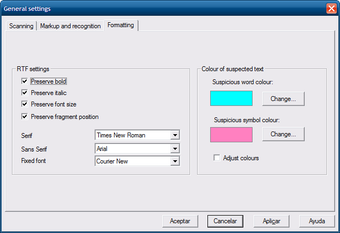
Окно настроек
В CuneiForm есть окно общих настроек с вкладками, связанными со сканированием, разметкой и форматированием. На вкладке Formatting видны параметры RTF: Preserve bold, Preserve italic, Preserve size, Preserve fragment position. Там же задаются шрифты Sans Serif и Fixed font, а для цветовой разметки используются поля Suspicious word colour и Suspicious symbol colour.
Ссылка:
Эти настройки важны при сохранении результата в RTF. Если нужно получить текст для последующей правки, полезно сохранить базовое форматирование: жирное начертание, курсив, размер и положение фрагментов. Если нужен чистый текст без оформления, лучше выбрать TXT или plain text в командной версии.
Цвет подозрительных слов и символов помогает при проверке результата. OCR-движок отмечает места, где уверенность ниже, и пользователь может быстрее найти фрагменты для ручной сверки.
Разметка и просмотр страницы
В рабочем окне CuneiForm видны текстовые блоки, выделенные рамками. Такой подход особенно важен для газетных страниц, инструкций и документов с несколькими колонками. OCR-система должна понять, где расположен заголовок, где основной текст, где изображение, а где таблица.
Автоматическая разметка экономит время на простых страницах, но сложные макеты требуют контроля. Если блок выделен неверно, качество текста ухудшается: строки могут смешаться, фрагменты могут пойти в неправильном порядке, а таблица превратится в набор плохо связанных строк. Поэтому при работе с документами сложной структуры сначала проверяется разметка, затем запускается распознавание.
Основные функции CuneiForm
Распознавание текста с изображений
CuneiForm распознаёт текст с изображений и сканов. Для Windows-версии подтверждена работа с JPG, BMP и PNG. Программа загружает изображение из локальной папки или получает его со сканера, затем запускает OCR и формирует редактируемый текст. В Windows-версии доступны загрузка изображений из папки или со сканирующего устройства, поддержка JPG, BMP, PNG, выбор языка, проверка орфографии, работа с таблицами и изображениями, экспорт в MS Word и RTF.
В реальной офисной задаче это выглядит так: есть бумажный документ, его сканируют или получают в виде картинки, затем открывают в CuneiForm, выбирают язык и запускают распознавание. После обработки текст переносится в редактор, где исправляются ошибки, восстанавливаются переносы и проверяются числа.
CuneiForm подходит для таких материалов:
страницы книг;
инструкции;
старые машинописные документы;
договоры и акты;
статьи;
сканы с принтера;
факсовые копии;
документы с русским и английским текстом;
изображения, где текст занимает большую часть страницы.
Не стоит ожидать одинакового качества на любом исходнике. OCR лучше работает с контрастным текстом на светлом фоне, без сильного перекоса, без размытия и с достаточным разрешением. Низкое качество скана приводит к ошибкам: буквы путаются с цифрами, знаки пунктуации исчезают, кириллица и латиница смешиваются.
Работа со сканером
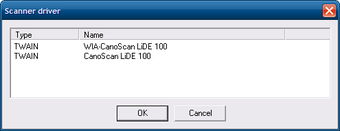
Windows-версия CuneiForm умеет получать изображение со сканера. В мастере распознавания пользователь выбирает источник: открыть готовый файл или использовать сканирование. При работе со сканером важны драйверы и выбранные параметры: размер страницы, разрешение, цветовой режим, яркость, контраст, границы листа.
Окно Scaner driver показывает список доступных TWAIN-драйверов. В примере интерфейса видны устройства WIA-CanoScan LiDE 100 и CanoScan LiDE 100. После выбора драйвера программа получает изображение и передаёт его на распознавание.
Ссылка:
Сканирование внутри CuneiForm удобно для единичных страниц. Для больших пачек документов лучше заранее подготовить файлы: выровнять страницы, убрать пустые поля, проверить ориентацию и одинаково назвать изображения. Тогда OCR становится более предсказуемым.
Распознавание языков
Командная версия CuneiForm поддерживает выбор языка через параметр -l. По умолчанию используется английский. Для русского текста указывается rus, для смешанного русского и английского — ruseng. Список языков включает Bulgarian, Croatian, Czech, Danish, Dutch, English, Estonian, French, German, Hungarian, Italian, Latvian, Lithuanian, Polish, Portuguese, Romanian, Russian, Serbian, Slovenian, Spanish, Swedish, Turkish и Ukrainian.
Для русскоязычных пользователей особенно важны два режима:
cuneiform -l rus -f text -o text.txt scan.png
cuneiform -l ruseng -f rtf -o text.rtf scan.png
Первый вариант подходит для полностью русского документа. Второй — для страницы, где есть русские абзацы, английские названия программ, латинские сокращения, адреса, технические обозначения, имена файлов или фрагменты интерфейса.
Неправильный язык — одна из частых причин плохого результата. Если русская страница распознаётся как английская, программа пытается подстроить символы под чужой алфавит. В итоге появляются странные латинские сочетания, пропадают кириллические буквы, ломаются окончания. Перед распознаванием всегда проверяется язык, а в смешанных документах выбирается смешанный режим.
Анализ структуры страницы
CuneiForm выполняет layout analysis — анализ макета. Это значит, что программа не ограничивается чтением строки слева направо. Она пытается определить, где находятся текстовые блоки, как они расположены, какие области относятся к таблицам, изображениям или заголовкам.
На простом одноколоночном документе автоматический анализ работает как вспомогательная функция: программа видит один поток текста и формирует результат. На странице с несколькими колонками, рамками, иллюстрациями и таблицами анализ становится важной частью OCR. Если структура определена правильно, порядок текста сохраняется лучше. Если блоки определены неверно, результат требует серьёзной ручной правки.
Для одноколоночных страниц в командной версии есть режим:
cuneiform --singlecolumn -l rus -f text -o result.txt scan.png
Параметр --singlecolumn отключает анализ макета и заставляет CuneiForm считать, что изображение содержит одну колонку текста. Это полезно для страниц книги, машинописных листов и простых инструкций, где автоматическое деление на блоки не требуется.
Режимы для факсов и матричной печати
CuneiForm поддерживает специальные режимы --fax и --dotmatrix. Они нужны для исходников, которые отличаются от обычной качественной печати.
Режим --fax рассчитан на текст, прошедший через факс. Факсовые копии часто имеют шум, ступенчатые контуры символов, слабый контраст и неровные линии. OCR-движку приходится отделять буквы от дефектов передачи.
Режим --dotmatrix рассчитан на текст, напечатанный матричным принтером. У таких документов буквы состоят из точек, а контур символа менее цельный, чем у лазерной печати. Обычный режим распознавания может ошибаться сильнее, потому что видит разорванные контуры.

Примеры команд:
cuneiform --fax -l eng -f text -o fax.txt fax_scan.tif
cuneiform --dotmatrix -l rus -f rtf -o matrix.rtf invoice.bmp
Эти режимы не превращают плохой исходник в идеальный документ. Они выбирают подходящий способ распознавания для конкретного типа изображения. После обработки факсов и матричной печати вычитка обязательна.
Проверка орфографии
CuneiForm использует словарную проверку результата. Она помогает обнаруживать подозрительные слова и исправлять типичные ошибки OCR. Проверка полезна при обычном печатном тексте: программа сопоставляет полученный результат со словарными формами и выделяет сомнительные места.
Словарная проверка не решает всё. В документах с фамилиями, техническими обозначениями, артикулами, юридическими формулировками, адресами и числами часть корректных слов может выглядеть подозрительно. Числа, даты, суммы, номера договоров и серийные номера проверяются вручную по изображению, а не только по словарю.
Частые ошибки после OCR:
0 вместо О и наоборот;
1 вместо l или I;
с кириллическая вместо c латинской;
потеря мягкого знака;
неправильные переносы слов;
слитные строки;
пропущенные точки и запятые;
неверное распознавание кавычек;
смешение русских и английских букв в одном слове.
Экспорт результата
В Windows-версии CuneiForm экспортирует результат в MS Word и RTF. RTF удобен как промежуточный формат: он открывается в Word, LibreOffice Writer и других текстовых редакторах, сохраняет часть форматирования и позволяет быстро перейти к ручной правке.
Командная версия поддерживает несколько форматов:
| Формат | Где полезен | Особенности |
|---|---|---|
| text | чистый текст без оформления | удобно для копирования, поиска и последующей обработки |
| smarttext | plain text с TeX-параграфами | полезно опытным пользователям, которым нужен структурированный текстовый результат |
| rtf | редактирование в Word и LibreOffice Writer | сохраняет больше структуры, чем TXT |
| html | просмотр в браузере и дальнейшая обработка | подходит для веб-ориентированных процессов |
| hocr | OCR-разметка для последующей обработки | полезно при создании поискового слоя или интеграциях |
| native | внутренний формат Cuneiform 2000 | нужен для совместимости с логикой CuneiForm |
Для обычного пользователя чаще всего достаточно RTF и TXT. RTF выбирается, когда важны абзацы, часть форматирования и дальнейшая правка в текстовом редакторе. TXT выбирается, когда нужен только текст без оформления.
Поддерживаемые форматы
Ввод изображений
Windows-версия работает с JPG, BMP и PNG. Это покрывает базовые офисные сценарии: скан в BMP, фотография или экспортированная страница в JPG, изображение без потерь в PNG. Для командной версии ввод зависит от сборки и графических библиотек. В документации Linux-порта указано, что при наличии ImageMagick++ Cuneiform обрабатывает изображения, которые умеет открывать ImageMagick; без него доступно чтение несжатых BMP.
Manpage Ubuntu описывает ввод шире: CuneiForm может обрабатывать любые одностраничные изображения, которые открывает GraphicsMagick.
Из этого следует практическое правило: перед работой с конкретной сборкой лучше использовать простые проверенные форматы — BMP, PNG, TIFF или JPG. Если файл не открывается, его конвертируют в поддерживаемое изображение внешним инструментом. Для PDF безопаснее сначала получить изображение страницы, потому что прямая работа с PDF не является базовой функцией CuneiForm во всех сборках.
Вывод текста
Выбор формата результата зависит от дальнейшей задачи.
RTF нужен, когда пользователь хочет открыть распознанный документ в Word или LibreOffice Writer и сохранить часть структуры. Такой формат подходит для договоров, писем, инструкций, статей и страниц с абзацами.
TXT нужен, когда оформление не важно. Это лучший вариант для заметок, цитат, поиска, вставки текста в другое приложение, подготовки данных для дальнейшей обработки.
HTML удобен, если результат нужно просмотреть в браузере или передать в процесс, где уже используется HTML-разметка.
hOCR нужен не каждому. Это формат для OCR-разметки, где текст связан с координатами и структурой страницы. Он полезен при последующей обработке, создании поискового слоя и технических сценариях.
Native относится к внутреннему формату Cuneiform 2000. Для обычной разовой работы он используется редко.
Как пользоваться CuneiForm: подготовка исходника
Перед распознаванием важнее всего подготовить изображение. OCR-движок работает с тем, что видит на странице. Если буквы размыты, строка перекошена, текст слишком мелкий, фон серый, а поля обрезаны, CuneiForm будет ошибаться чаще.
Хороший исходник для CuneiForm:
страница расположена ровно;
текст контрастный;
буквы не слипаются;
нет сильного шума;
поля не закрывают строки;
ориентация страницы правильная;
разрешение достаточно для чтения мелкого шрифта;
язык документа выбран правильно;
таблицы и многостолбцовые страницы проверены перед запуском OCR.
Для старых сканов полезно сначала выровнять страницу, убрать лишние поля и повысить контраст. Если документ состоит из нескольких страниц, каждую страницу лучше сохранить отдельным изображением с понятным именем. Это упрощает проверку результата и исправление ошибок.
Подготовка скана перед OCR
Отсканировать страницу без обрезания текста по краям.
Проверить, что страница не повернута на 90 или 180 градусов.
Убрать сильный наклон.
Проверить, что мелкие буквы различимы.
Сохранить изображение в формате, который открывает используемая сборка CuneiForm.
Для русского документа выбрать русский язык.
Для смешанного русского и английского текста использовать смешанный режим.
После распознавания сверить результат с изображением.
Отдельное внимание нужно уделять таблицам. Windows-версия CuneiForm работает с таблицами, а Linux-порт имеет ограничение: таблицы в нём не распознаются как отдельная структура. Поэтому сложные табличные документы лучше обрабатывать в Windows-версии или в другом OCR-инструменте.
Как распознать изображение в Windows-версии
Windows-сценарий строится вокруг мастера Recognition Wizard. Его логика понятна: сначала источник изображения, затем параметры распознавания, потом получение результата.
Порядок работы:
Открыть CuneiForm.
Запустить Recognition Wizard.
Выбрать источник: готовое изображение или сканер.
При выборе изображения указать файл JPG, BMP или PNG.
При выборе сканера выбрать драйвер в окне Scaner driver.
Указать язык документа.
Проверить изображение в рабочей области.
Запустить распознавание.
Просмотреть результат в нижней области или в окне текста.
Сохранить результат в RTF или передать в Word.
Выполнить вычитку по исходному изображению.
Во время работы пользователь видит исходную страницу и результат OCR. Это удобно для быстрой сверки: можно сравнить сомнительное слово с изображением, проверить цифры и убедиться, что строки не перепутались.
Для простого скана книги достаточно открыть изображение, выбрать язык и запустить распознавание. Для документа с несколькими колонками сначала нужно посмотреть разметку: синие рамки должны соответствовать реальным текстовым областям. Если страница разделена неправильно, итоговый текст пойдёт в неверном порядке.
Проверка результата после распознавания
После OCR текст нельзя сразу считать готовым документом. Даже при хорошем исходнике проверяются:
заголовки;
числа;
даты;
фамилии;
сокращения;
адреса;
названия организаций;
номера договоров;
пунктуация;
переносы;
таблицы;
слова с латинскими символами внутри кириллицы.

Для обычной статьи или инструкции достаточно вычитать текст целиком. Для юридического, финансового, архивного или технического документа нужна посимвольная сверка важных фрагментов. OCR-ошибка в сумме, дате или номере документа меняет смысл.
Как пользоваться CuneiForm через командную строку
Командный режим CuneiForm удобен для пользователей Linux, FreeBSD и для тех, кто автоматизирует обработку документов. Вместо мастера используется команда с параметрами.
Базовая структура:
cuneiform -l язык -f формат -o файл_результата файл_изображения
Пример для русского текста:
cuneiform -l rus -f rtf -o result.rtf scan.png
Пример для английского текста:
cuneiform -l eng -f text -o result.txt page.tif
Пример для смешанного русского и английского текста:
cuneiform -l ruseng -f html -o result.html document.bmp
Пример для факсовой копии:
cuneiform --fax -l rus -f text -o fax.txt fax_page.tif
Пример для текста с матричного принтера:
cuneiform --dotmatrix -l eng -f rtf -o matrix.rtf invoice.bmp
Пример для одноколоночной страницы:
cuneiform --singlecolumn -l rus -f text -o book_page.txt page.png
Командная строка хороша тем, что один и тот же набор параметров можно повторять. Например, для папки с однотипными страницами книги пользователь выбирает язык, формат и режим один раз, затем запускает обработку по файлам. После этого остаётся объединить результат и выполнить вычитку.
Что означают основные параметры
| Параметр | Назначение |
|---|---|
| -l rus | русский язык распознавания |
| -l eng | английский язык распознавания |
| -l ruseng | смешанный русский/английский текст |
| -f text | обычный текст |
| -f rtf | RTF-документ |
| -f html | HTML-документ |
| -f hocr | hOCR-разметка |
| -o result.txt | имя файла результата |
| --singlecolumn | обработка страницы как одной колонки |
| --fax | режим для факсов |
| --dotmatrix | режим для матричной печати |
Если не указать файл результата через -o, CuneiForm создаёт файл с именем cuneiform-out.[format], где расширение зависит от выбранного формата.
Как использовать Cuneiform-Qt
Cuneiform-Qt — графическая оболочка для CuneiForm в Linux. Она не заменяет OCR-движок, а даёт простое окно для тех, кто не хочет каждый раз запускать терминал. Интерфейс состоит из меню File, Settings, Help, кнопок Open image, Recognize text, Save result и двух областей: Source Image и Recognized text.
Порядок работы:
Нажать Open image.
Выбрать изображение со сканом.
Проверить, что страница видна в области Source Image.
Нажать Recognize text.
Посмотреть результат в области Recognized text.
Нажать Save result.
Cuneiform-Qt сохраняет результат в HTML. Такой вариант удобен для простой демонстрации OCR: слева виден исходник, справа появляется распознанный текст. Для больших архивов и повторяющихся операций командная строка остаётся гибче.
Системные требования
Windows-версия
Windows-версия CuneiForm относится к классическим настольным программам. В каталогах программы указывались Windows XP/Vista, Windows All и установочный файл размером около 32 MB. CuneiForm работает с изображениями из локальных папок и со сканирующего устройства, поддерживает JPG, BMP и PNG.
Для работы нужны:
установленная Windows-система, совместимая с выбранной сборкой;
доступ к папке с изображениями или подключённый сканер;
драйвер сканера, если используется сканирование из программы;
достаточное место для изображений и результата;
текстовый редактор для правки RTF или TXT.
CuneiForm не требует мощного компьютера по современным меркам. Главный практический фактор — не процессор, а качество исходных изображений и корректная работа сканера.
Linux-порт
Cuneiform for Linux проверялся на Linux, FreeBSD, OS X и Windows-сборках через MSVC, MinGW и Cygwin. Для порта указаны ограничения: x86 и amd64, отсутствие распознавания таблиц.
Для сборки и запуска в Unix-подобных системах используются CMake и стандартные инструменты компиляции. При наличии ImageMagick++ программа обрабатывает форматы, которые открывает ImageMagick; без него доступно чтение несжатых BMP.
Для обычного пользователя Linux важнее не сборка из исходников, а рабочая связка:
CuneiForm как OCR-движок;
терминал для запуска команд;
графическая оболочка Cuneiform-Qt, YAGF или другая программа;
инструмент подготовки изображений;
текстовый редактор для проверки результата.
Что проверить перед работой
Перед распознаванием нужно заранее понять четыре вещи:
| Вопрос | Почему это важно |
|---|---|
| На каком языке документ? | неправильный язык резко снижает качество OCR |
| Какой формат результата нужен? | RTF удобен для правки, TXT — для чистого текста, hOCR — для технической обработки |
| Есть ли таблицы? | Windows-версия работает с таблицами, Linux-порт имеет ограничение |
| Достаточно ли качество изображения? | плохой скан даст много ошибок даже при правильных настройках |
Для разовой задачи на Windows обычно достаточно мастера. Для регулярной обработки сканов лучше заранее выработать единый формат: одинаковое разрешение, одинаковое именование файлов, один язык, один формат результата и отдельный этап вычитки.
Преимущества и ограничения
Плюсы:
программа работает локально и не требует отправки документов в онлайн-сервис;
есть поддержка русского языка;
есть смешанный режим русского и английского текста;
Windows-версия использует мастер Recognition Wizard;
можно получать изображения из локальной папки или со сканера;
поддерживаются JPG, BMP и PNG в Windows-версии;
командная версия поддерживает TXT, RTF, HTML, hOCR, smarttext и native;
есть режимы для факсов, матричной печати и одноколоночных страниц;
OCR-ядро Cuneiform открыто под BSD-лицензией;
программу можно использовать в технических сценариях через командную строку;
есть графические оболочки для Linux-сценариев;
RTF-вывод удобен для дальнейшего редактирования.
Минусы:
интерфейс Windows-версии выглядит устаревшим;
результат требует ручной вычитки;
качество сильно зависит от разрешения, контраста и ровности скана;
Linux-порт не распознаёт таблицы как структуру;
прямая работа с PDF не является универсальной базовой функцией CuneiForm;
в Linux для удобной работы часто нужна отдельная графическая оболочка;
сложные макеты с несколькими колонками и иллюстрациями требуют контроля разметки;
рукописный текст не относится к рабочему сценарию CuneiForm;
старые факсы и копии с шумом дают больше ошибок;
для юридических и финансовых документов нужна посимвольная проверка важных данных.
Сравнение с аналогами
CuneiForm и ABBYY FineReader PDF
ABBYY FineReader PDF — современный коммерческий OCR/PDF-комплекс. Он рассчитан не только на распознавание текста, но и на работу с PDF-документами: конвертацию, редактирование, защиту, сравнение, совместную работу и интеграцию в цифровой документооборот. ABBYY FineReader PDF используется для оцифровки, поиска, редактирования, защиты, обмена и совместной работы с документами.
CuneiForm проще и уже. Она полезна, когда нужно локально распознать изображение или скан и получить редактируемый текст без покупки комплексного продукта. FineReader PDF уместнее для регулярной офисной работы с PDF, многостраничными документами, таблицами, сохранением структуры и задачами с высокой ценой ошибки.
| Критерий | CuneiForm | ABBYY FineReader PDF |
|---|---|---|
| Тип | OCR-программа и OCR-движок | OCR/PDF-комплекс |
| Основной сценарий | текст из скана или изображения | полный цикл работы с PDF и сканами |
| Стоимость подхода | бесплатная программа | коммерческий продукт |
| Интерфейс | классический, устаревший | современный офисный интерфейс |
| Командная строка | есть в Linux-порте | основной сценарий не терминальный |
| Таблицы | есть в Windows-версии, нет в Linux-порте | сильнее подходит для сложных документов |
| Для кого | пользователи с простыми OCR-задачами, энтузиасты, Linux-пользователи | офис, бизнес, архивы, сложные PDF-процессы |
Выбор между ними зависит от задачи. Для единичного скана с печатным текстом CuneiForm достаточно. Для регулярной обработки PDF, договоров, отчётов и таблиц рациональнее использовать FineReader PDF.
CuneiForm и Tesseract OCR
Tesseract OCR — известный открытый OCR-движок. Он не включает собственную графическую программу и чаще используется через командную строку, API или внешние оболочки. Tesseract поддерживает вывод в plain text, hOCR, PDF, invisible-text-only PDF, TSV, ALTO и PAGE.
CuneiForm и Tesseract похожи тем, что оба могут работать локально и подходят для технических OCR-сценариев. Разница в профиле. CuneiForm исторически интересен поддержкой русского языка, RTF/HTML/hOCR-выводом и Windows-версией с мастером. Tesseract чаще встречается в современных проектах, автоматизации и разработке, но требует отдельного интерфейса или собственной обвязки.
| Критерий | CuneiForm | Tesseract OCR |
|---|---|---|
| Тип | OCR-система с Windows-интерфейсом и консольным портом | OCR-движок без собственного GUI |
| Русский язык | поддерживается | поддерживается через языковые данные |
| Смешанный русский/английский режим | есть ruseng | настраивается выбором языков |
| Форматы | TXT, RTF, HTML, hOCR, smarttext, native | TXT, hOCR, PDF, TSV, ALTO, PAGE |
| Для новичка | Windows-версия проще за счёт мастера | удобнее через оболочки |
| Для разработчика | полезен как открытый OCR-движок | шире используется в современных интеграциях |
Tesseract сильнее как современный технический стандарт. CuneiForm удобнее рассматривать как самостоятельную OCR-программу с исторически важной ролью и понятным Windows-сценарием.
CuneiForm и NAPS2
NAPS2 — программа для сканирования документов в PDF и изображения. Она бесплатная, открытая, работает на Windows, Mac и Linux, поддерживает сканирование в PDF, TIFF, JPEG и PNG, а также OCR для поискового текста в сканированных документах.
NAPS2 удобнее, когда задача начинается со сканера: нужно быстро получить многостраничный PDF, переставить страницы, сохранить документ и добавить поисковый слой. CuneiForm лучше подходит как отдельный OCR-инструмент, когда уже есть изображение и нужен редактируемый текст.
| Критерий | CuneiForm | NAPS2 |
|---|---|---|
| Главная задача | распознавание текста | сканирование и сборка документов |
| PDF-процесс | не главный сценарий | один из основных сценариев |
| OCR | основная функция | дополнительная функция для поиска текста |
| Работа с изображениями | распознавание изображения | сканирование, сохранение и организация страниц |
| Подходит для | извлечения текста | создания сканов и PDF-архива |
Если нужно отсканировать папку документов и сохранить всё в PDF, NAPS2 удобнее. Если уже есть изображение страницы и нужно получить RTF или TXT, CuneiForm работает прямее.
CuneiForm и OCRFeeder
OCRFeeder — система анализа макета и OCR, которая автоматически определяет содержимое изображения, отделяет графику от текста и выполняет распознавание. Основной формат результата — ODT.
CuneiForm в этой паре — OCR-движок и отдельная программа. OCRFeeder — оболочка и система подготовки документа, которая использует OCR-движки. Сравнение важно для Linux-пользователей: CuneiForm может выполнять распознавание, а OCRFeeder организует работу с областями, макетом и выводом в офисный формат.
| Критерий | CuneiForm | OCRFeeder |
|---|---|---|
| Тип | OCR-движок и программа | графическая программа для анализа макета и OCR |
| Основной формат | TXT, RTF, HTML, hOCR | ODT |
| Роль в процессе | распознаёт текст | готовит структуру документа и вызывает OCR |
| Для кого | пользователи, которым нужен движок или простой OCR | пользователи Linux, которым нужен графический процесс |
OCRFeeder удобен, когда нужно работать с макетом и офисным результатом. CuneiForm полезен как движок распознавания внутри такого процесса.
CuneiForm и FreeOCR
FreeOCR — простая Windows-программа для распознавания текста. Она ближе к CuneiForm по аудитории: пользователь открывает изображение или скан, запускает OCR и получает текст. Отличие в том, что CuneiForm имеет собственную историю как система Cognitive Technologies, открытое OCR-ядро и командный Linux-порт.

FreeOCR чаще воспринимается как утилита для разовых задач. CuneiForm интереснее там, где важны русский язык, история продукта, командная работа и RTF/HTML/hOCR-вывод.
CuneiForm и PDF-инструменты
CuneiForm нельзя напрямую сравнивать с PDFsam, PDF Shaper Free, PDFCreator или doPDF, потому что они решают другие задачи. PDFsam разделяет и объединяет PDF, PDF Shaper Free выполняет операции с PDF, PDFCreator и doPDF создают PDF через виртуальную печать. CuneiForm распознаёт текст.
Практический рабочий процесс часто объединяет несколько программ:
Сканирование страницы или получение изображения.
Подготовка изображения.
Распознавание в CuneiForm.
Правка текста в Word или LibreOffice Writer.
При необходимости создание PDF через PDF-инструмент.
В такой цепочке CuneiForm занимает конкретное место: OCR между изображением и редактируемым текстом.
Отзывы пользователей и профильных журналов
Мнение профильных изданий
Softpedia оценила CuneiForm в 4.0/5 и описала её как быстрый и понятный OCR-инструмент для превращения сканов в редактируемый текст. В обзоре выделены Recognition Wizard, загрузка изображений из папки или со сканера, поддержка JPG, BMP и PNG, выбор языка, проверка орфографии, работа с таблицами и изображениями, экспорт в MS Word и RTF.
ITC в материале OCR CuneiForm V.12: распознаем бесплатно подчёркивал шрифтонезависимость системы, поддержку более 20 языков, русский, украинский и смешанный русский/английский текст, автоматическое нахождение таблиц и изображений, а также пользу ручной разметки при ошибочном определении областей.
Мир ПК рассматривал CuneiForm в контексте открытия кода и инициативы Cognitive Technologies. В выпуске №02 за 2008 год программа описывалась как важный продукт компании на 15-м году её существования; отдельно отмечалось распространение технологии вместе с большим числом моделей сканеров.
ICT-Online освещал открытие кода OCR Cuneiform и подчёркивал, что публикация исходных кодов создаёт возможность использовать OCR в разных программных продуктах и привлекать Open Source-сообщество к развитию технологии.
Усреднённое мнение пользователей
Пользовательские оценки CuneiForm складываются вокруг нескольких повторяющихся тем.
Положительно воспринимаются:
бесплатность;
поддержка русского языка;
возможность работать без интернета;
понятный Windows-мастер;
распознавание печатного текста с обычных сканов;
сохранение результата в редактируемом виде;
командная работа в Linux;
открытый исходный код OCR-ядра.
Критика обычно касается другого:
интерфейс выглядит старым;
результат требует исправлений;
сложные макеты не всегда разбираются правильно;
низкокачественные изображения дают много ошибок;
Linux-порт не закрывает все возможности Windows-версии;
для PDF-процессов нужны дополнительные программы.
На форумах и в обсуждениях CuneiForm часто сравнивали с ABBYY FineReader и OmniPage. Оценка обычно сводилась к тому, что CuneiForm интересен как бесплатная и открытая альтернатива, но не равен полноценным коммерческим OCR-комплексам для сложного профессионального документооборота. В обсуждении PortableApps программу прямо называли сильным freeware/open source OCR-инструментом, но не сопоставляли её с FineReader и OmniPage по уровню коммерческих пакетов.
Для честной оценки это важнее рекламных обещаний. CuneiForm хорош там, где пользователь готов проверить результат. Там, где ошибка недопустима, нужен либо более современный OCR-комплекс, либо двойная ручная сверка.
Типичные ошибки при работе с CuneiForm
Неправильный язык распознавания
Русский текст нельзя распознавать как английский. Визуально часть букв похожа, но OCR-движок опирается на язык и словарь. Неправильный язык приводит к смешению латиницы и кириллицы, странным словам и ошибкам в окончаниях.
Правильный подход:
русский документ — rus;
английский документ — eng;
русский документ с английскими названиями — ruseng;
многоязычный документ — язык выбирается по основному тексту, затем результат проверяется вручную.
Слабый скан
Размытая страница, серый фон, тёмные поля, низкое разрешение и перекос ухудшают результат. CuneiForm не восстанавливает текст из любого изображения. OCR-система распознаёт видимые символы; если буквы повреждены, программа ошибается.
Перед OCR полезно:
выровнять страницу;
убрать лишние поля;
усилить контраст;
проверить ориентацию;
сохранить без чрезмерного сжатия;
не использовать фотографию с перспективным искажением, если можно сделать нормальный скан.
Игнорирование разметки
На многостолбцовой странице автоматическая разметка может определить блоки не в том порядке. Тогда результат будет выглядеть как набор строк из разных частей страницы. В CuneiForm нужно смотреть на рамки текстовых блоков до сохранения результата.
Особенно осторожно обрабатываются:
газеты;
журналы;
инструкции с иллюстрациями;
бланки;
таблицы;
страницы с боковыми колонками;
сканы с заметками на полях.
Ожидание распознавания рукописного текста
CuneiForm предназначен для печатного текста. Рукописные записи, подписи, конспекты, заметки на полях и декоративные шрифты не относятся к рабочему сценарию программы. Если на странице есть рукописная подпись, её нужно воспринимать как изображение, а не как текст для OCR.
Сохранение в неподходящий формат
TXT удобен для чистого текста, но не сохраняет оформление. RTF лучше подходит для правки в текстовом редакторе. HTML полезен, если результат нужен в браузере или для дальнейшей обработки. hOCR нужен для технических процессов.
Ошибка возникает, когда пользователь сохраняет сложный документ в TXT и ожидает сохранения структуры. Для таблиц, заголовков и абзацев лучше выбирать RTF и проверять результат вручную.
Отсутствие вычитки
Самая опасная ошибка — считать OCR-результат готовым документом. CuneiForm может дать хороший текст, но отдельные ошибки остаются. В обычной статье это неприятно, в договоре или финансовом документе — критично.
Обязательная проверка:
суммы;
даты;
имена;
адреса;
номера документов;
формулы;
единицы измерения;
таблицы;
текст мелким шрифтом.
Практические сценарии использования
Разовая офисная задача
Пользователь получил скан договора, письма или инструкции и хочет скопировать текст. В этом случае CuneiForm открывает изображение, распознаёт страницу и сохраняет результат в RTF. Затем документ открывается в Word или LibreOffice Writer, исправляются ошибки и убираются лишние переносы.
Оптимальные настройки:
язык: русский или ruseng;
формат: RTF;
режим: обычный, если страница простая;
проверка: полностью вычитать текст после OCR.

Архивная работа
Для старых документов CuneiForm полезен как локальный инструмент. Архивные страницы часто содержат машинописный текст, старую печать, слабый контраст и шум. Здесь важна подготовка изображения: выравнивание, контраст, устранение лишних полей.
Для архивной работы лучше сохранять два файла:
исходное изображение без изменений;
распознанный текст после правки.
Так сохраняется возможность вернуться к оригиналу и проверить спорные места.
Работа с книгой
При распознавании книги лучше обрабатывать страницы по одной или небольшими группами. Книжные развороты часто имеют изгиб у корешка, тень и неровную строку. OCR лучше работает с отдельной ровной страницей, чем с разворотом.
Рекомендуемый процесс:
Получить изображения страниц.
Выровнять и обрезать поля.
Распознать страницы в TXT или RTF.
Объединить текст.
Удалить лишние переносы.
Проверить заголовки и номера страниц.
Сверить сомнительные фрагменты с изображением.
Технический сценарий в Linux
В Linux CuneiForm удобен для автоматизации. Пользователь готовит изображения и запускает OCR командой. Для однотипных файлов можно использовать цикл оболочки, а результат сохранять в TXT, RTF или HTML.
Пример:
for file in *.png; do
cuneiform -l rus -f text -o "${file%.png}.txt" "$file"
done
Такой сценарий подходит для технической обработки, но результат всё равно проверяется. Автоматизация ускоряет получение текста, а не заменяет редактуру.
Конфиденциальные документы
CuneiForm работает локально. Это важно для документов, которые нельзя отправлять в онлайн-сервисы: договоры, внутренние инструкции, архивные материалы, персональные данные, служебные бумаги. Локальное OCR снижает риск передачи файла третьей стороне.
При работе с конфиденциальными документами нужно дополнительно контролировать:
где хранятся исходные изображения;
кто имеет доступ к папке с результатом;
удаляются ли временные файлы;
не отправляется ли документ в облачный конвертер на соседнем этапе;
корректно ли уничтожаются черновики после завершения работы.
Безопасность и конфиденциальность
Главное преимущество локального OCR — документ остаётся на компьютере. CuneiForm не требует облачной обработки для основной задачи распознавания. Это удобно для пользователей, которые работают с внутренними файлами, персональными данными или архивными материалами.
Безопасный рабочий процесс выглядит так:
Получить скан локально.
Сохранить исходник в отдельную папку.
Распознать текст в CuneiForm.
Проверить результат.
Сохранить исправленный файл.
Удалить временные копии, если они больше не нужны.
Не загружать документ в сторонние онлайн-конвертеры без необходимости.
Устаревшие настольные программы требуют внимательности к установочным файлам. Для рабочей машины лучше использовать проверенный источник файла, проверку антивирусом и отдельную папку для документов. Но в самой статье о программе важнее не место получения файла, а рабочая логика: CuneiForm обрабатывает текст локально и не требует внешнего сервера для OCR.
Для кого подходит CuneiForm
Новичку
CuneiForm подходит новичку, если задача проста: открыть скан, выбрать язык, получить текст и вручную исправить ошибки. Windows-версия с Recognition Wizard снижает порог входа: мастер сам ведёт по шагам и не требует знания команд.
Лучший сценарий для новичка:
один документ;
чёткий печатный текст;
русский или английский язык;
сохранение в RTF;
последующая правка в текстовом редакторе.
Новичку не стоит начинать с командной строки, сложных таблиц и многостолбцовых газетных страниц. Для первого использования лучше взять простой скан одной страницы.
Опытному пользователю
Опытному пользователю CuneiForm интересен как OCR-движок. Командная строка позволяет задавать язык, формат, режим страницы и имя результата. Это удобно для повторяющихся задач и технических процессов.
Опытный пользователь получает больше контроля:
выбирает rus, eng, ruseng;
задаёт -f rtf, -f html, -f hocr;
использует --singlecolumn, --fax, --dotmatrix;
обрабатывает папки изображений;
подключает внешнюю подготовку изображений;
использует hOCR для дальнейших операций.
Пользователю Linux
В Linux CuneiForm подходит тем, кто спокойно работает с терминалом или использует оболочки. Чистая командная версия не даёт привычного мастер-окна, зато хорошо вписывается в скрипты и пакетные процессы.
Для графической работы в Linux удобнее Cuneiform-Qt или YAGF. Cuneiform-Qt минималистичен: открыть изображение, распознать, сохранить. YAGF шире: подготовка изображения, выбор областей, язык, исправление результата, сохранение или копирование текста.
Архивисту и редактору
CuneiForm полезен для переноса старых печатных материалов в редактируемый вид. Редактор получает текст, который можно чистить, приводить к единому стилю, проверять и публиковать. Архивист получает возможность сделать старые документы доступными для поиска.
В этом сценарии важно сохранять связь с оригиналом. Распознанный текст не заменяет скан, пока не выполнена сверка. Для архивных документов лучше хранить изображение и отредактированный текст вместе.
Офисному пользователю
Офисный пользователь применяет CuneiForm для типовых задач: распознать письмо, акт, инструкцию, старый приказ, страницу договора. Важный плюс — результат можно открыть в Word или RTF-редакторе и продолжить работу.
Ограничение: CuneiForm не управляет PDF-документооборотом. Если в офисе регулярно работают с PDF, аннотациями, подписями, защитой и сравнением документов, CuneiForm становится только одним звеном, а не всей системой.
Когда лучше выбрать другую программу
CuneiForm не нужно использовать там, где задача выходит за пределы её профиля.
Выберите другой инструмент, если нужно:
редактировать PDF-страницы;
сравнивать версии документов;
распознавать сложные таблицы в Linux;
создавать поисковый PDF с сохранением исходной страницы;
массово сканировать документы в PDF;
работать с рукописным текстом;
обрабатывать документы без ручной вычитки;
получать современный интерфейс и поддержку сложных офисных процессов.
Для PDF-редактирования больше подходит ABBYY FineReader PDF или PDF Commander. Для просмотра документов — Adobe Acrobat Reader, Foxit Reader, Sumatra PDF. Для сканирования в PDF — WinScan2PDF и PaperScan Free. Для разделения и сборки PDF — PDFsam.
Частые вопросы
CuneiForm распознаёт русский язык?
Да. Русский язык поддерживается. В командной версии используется код rus. Для смешанного русского и английского текста используется ruseng.
Можно ли распознать русский и английский текст на одной странице?
Да. Для командной версии предусмотрен смешанный режим ruseng. Он полезен для документов, где рядом с русскими абзацами есть английские названия, технические термины, имена файлов, маркировка или фрагменты интерфейса.
Подходит ли CuneiForm для рукописного текста?
Нет. CuneiForm применяется для печатного текста. Рукописные заметки, подписи и конспекты не относятся к её рабочему сценарию.
Можно ли использовать CuneiForm без интернета?
Да. CuneiForm выполняет OCR локально. Это один из сильных практических аргументов в пользу программы при работе с внутренними документами.
Можно ли распознавать PDF?
CuneiForm работает с изображениями. Для PDF безопасный процесс такой: сначала получить изображение страницы, затем распознать его в CuneiForm. Прямая работа с PDF зависит от внешних инструментов и оболочек, поэтому её не стоит считать базовой функцией самой программы.
Какой формат результата выбрать?
Для дальнейшей правки лучше RTF. Для чистого текста — TXT. Для браузера или технической обработки — HTML. Для OCR-разметки — hOCR.
Почему результат получился с ошибками?
Чаще всего причина в слабом скане, неправильном языке, перекосе страницы, низком контрасте, сложной верстке или мелком шрифте. OCR всегда требует проверки, а документы с числами и юридически значимыми данными сверяются особенно внимательно.
Чем CuneiForm отличается от Tesseract?
CuneiForm — OCR-система с Windows-интерфейсом, историей Cognitive Technologies, поддержкой RTF/HTML/hOCR и отдельным Linux-портом. Tesseract — более распространённый современный OCR-движок без собственного графического интерфейса, который часто используют в разработке и автоматизации.
Чем CuneiForm отличается от ABBYY FineReader PDF?
CuneiForm — бесплатная OCR-программа для получения текста из изображения. ABBYY FineReader PDF — коммерческий комплекс для OCR и полноценной работы с PDF. CuneiForm проще и уже; FineReader PDF подходит для регулярных профессиональных PDF-задач.
Практический вывод
CuneiForm OCR стоит рассматривать как конкретную программу для распознавания печатного текста, а не как универсальный офисный пакет. Её сильные стороны — локальная обработка, бесплатность, поддержка русского языка, смешанный русский/английский режим, RTF/TXT/HTML/hOCR-вывод и возможность работать через командную строку.
Для разовой задачи на Windows CuneiForm подходит, если нужно превратить скан или изображение в редактируемый текст и пользователь готов вычитать результат. Для Linux-сценариев программа полезна как OCR-движок, особенно вместе с Cuneiform-Qt или YAGF. Для архивной работы она удобна при обработке старых печатных страниц, машинописных документов и книг, но требует аккуратной подготовки изображений.
Для сложных PDF-документов, таблиц, регулярного документооборота и материалов с высокой ценой ошибки лучше использовать более современный OCR/PDF-комплекс или строить процесс из нескольких программ. CuneiForm остаётся хорошим выбором там, где задача сформулирована точно: распознать печатный текст со скана, сохранить его в редактируемом виде и вручную довести результат до чистого документа.
Список изменений
Коммерческий этап Cognitive Technologies:
- CuneiForm появилась как коммерческий OCR-продукт Cognitive Technologies. В истории программы важен контекст: в 1990-е и 2000-е годы OCR не был обычной функцией каждого офисного пакета. Распознавание текста требовало отдельного движка, словарей, алгоритмов анализа страницы, работы со сканерами и правил восстановления структуры документа.
- CuneiForm была программой, которой комплектовались модели сканеров Hewlett-Packard, Canon, Mustek, Kodak, Fujitsu, Primetex, Olivetti и других производителей.
- На этом этапе CuneiForm была не просто небольшой утилитой, а частью рынка распознавания документов. Программа решала задачи, которые сегодня воспринимаются как базовые: сканирование страницы, выделение текстовых зон, распознавание символов, сохранение результата в редактируемом виде.
Переход к бесплатному распространению:
- В конце 2007 года CuneiForm стала бесплатной. Этот переход важен для понимания программы: CuneiForm перестала быть только коммерческим OCR-продуктом и стала доступным инструментом для пользователей, которым нужна программа для распознавания текста без покупки дорогого пакета.
- Решение о бесплатном распространении было связано с инициативой Распознавание должно быть на каждом компьютере. После этого CuneiForm начали обсуждать не только как продукт Cognitive Technologies, но и как технологическую базу для свободного OCR. В декабре 2007 года также анонсировалось открытие исходных текстов.
- Для обычного пользователя это означало простой результат: появилась бесплатная OCR программа, которая распознаёт русский текст, английский текст и смешанные документы, не требуя перехода в онлайн-сервис.
Открытие исходного кода:
- графическая Windows-версия с мастером распознавания;
- консольный OCR-движок, который можно запускать из терминала и подключать к другим инструментам.
Linux-порт и командная версия:
- Linux-порт CuneiForm превратил программу в инструмент для терминала. Такой формат особенно удобен для опытных пользователей: можно обрабатывать файлы через команды, указывать язык, выбирать формат результата и включать специальные режимы для факса, матричной печати или одноколоночной страницы.
- Командная версия принимает структуру:
- cuneiform [--dotmatrix] [--fax] [--singlecolumn] [-f format] [-l language] [-o output] input Эта форма отражает основную логику программы: есть входное изображение, язык, формат вывода и дополнительные параметры OCR. По умолчанию CuneiForm распознаёт английский текст и создаёт обычный текстовый результат. Язык меняется параметром -l, формат — параметром -f, имя файла результата — параметром -o.
- В Linux-порте есть подтверждённые ограничения. Он рассчитан на x86 и amd64, а распознавание таблиц в этом порте не реализовано. Эти ограничения важны при выборе инструмента для архивной или офисной обработки: Windows-версия и Linux-порт не полностью одинаковы по возможностям.
Графические оболочки вокруг CuneiForm:
- После открытия OCR-ядра появились графические оболочки, которые используют CuneiForm как движок. Cuneiform-Qt — простой пример такого подхода. Это GUI-фронтенд на Qt4 для Linux: он открывает отсканированное изображение, показывает его в области предварительного просмотра, запускает распознавание через Cuneiform и сохраняет результат в HTML.
- Ссылка: https://en.altlinux.org/Images.en.altlinux.org/d/dc/Cuneiform-Qt-En.png
- В Cuneiform-Qt интерфейс сводится к нескольким действиям: Open image, Recognize text, Save result. Слева находится область Source Image, справа — Recognized text. Такой формат показывает, как CuneiForm используется в Linux-сценарии: движок выполняет распознавание, а оболочка даёт кнопки и окно для просмотра результата.
- Ещё один пример — YAGF. Это графическая оболочка для Cuneiform и Tesseract: она открывает уже отсканированные изображения, получает новые изображения через XSane, позволяет подготовить страницу к распознаванию, выбрать области и язык, а затем исправить результат в редакторе, сохранить его или скопировать в буфер обмена.

{kind=link}
Оставте свой отзыв о CuneiForm